Posts tagged ‘social networks’
Link Prediction by De-anonymization: How We Won the Kaggle Social Network Challenge
The title of this post is also the title of a new paper of mine with Elaine Shi and Ben Rubinstein. You can grab a PDF or a web-friendly HTML version generated using my Project Luther software.
A brief de-anonymization history. As early as the first version of my Netflix de-anonymization paper with Vitaly Shmatikov back in 2006, a colleague suggested that de-anonymization can in fact be used to game machine-learning contests—by simply “looking up” the attributes of de-anonymized users instead of predicting them. We off-handedly threw in paragraph in our paper discussing this possibility, and a New Scientist writer seized on it as an angle for her article.[1] Nothing came of it, of course; we had no interest in gaming the Netflix Prize.
During the years 2007-2009, Shmatikov and I worked on de-anonymizing social networks. The paper that resulted (PDF, HTML) showed how to take two graphs representing social networks and map the nodes to each other based on the graph structure alone—no usernames, no nothing. As you might imagine, this was a phenomenally harder technical challenge than our Netflix work. (Backstrom, Dwork and Kleinberg had previously published a paper on social network de-anonymization; the crucial difference was that we showed how to put two social network graphs together rather than search for a small piece of graph-structured auxiliary information in a large graph.)
The context for these two papers is that data mining on social networks—whether online social networks, telephone call networks, or any type of network of links between individuals—can be very lucrative. Social networking websites would benefit from outsourcing “anonymized” graphs to advertisers and such; we showed that the privacy guarantees are questionable-to-nonexistent since the anonymization can be reversed. No major social network has gone down this path (as far as I know), quite possibly in part because of the two papers, although smaller players often fly under the radar.
The Kaggle contest. Kaggle is a platform for machine learning competitions. They ran the IJCNN social network challenge to promote research on link prediction. The contest dataset was created by crawling an online social network—which was later revealed to be Flickr—and partitioning the obtained edge set into a large training set and a smaller test set of edges augmented with an equal number of fake edges. The challenge was to predict which edges were real and which were fake. Node identities in the released data were obfuscated.
There are many, many anonymized databases out there; I come across a new one every other week. I pick de-anonymization projects if it will advance the art significantly (yes, de-anonymization is still partly an art), or if it is fun. The Kaggle contest was a bit of both, and so when my collaborators invited me to join them, it was too juicy to pass up.
The Kaggle contest is actually much more suitable to game through de-anonymization than the Netflix Prize would have been. As we explain in the paper:
One factor that greatly affects both [the privacy risk and the risk of gaming]—in opposite directions—is whether the underlying data is already publicly available. If it is, then there is likely no privacy risk; however, it furnishes a ready source of high-quality data to game the contest.
The first step was to do our own crawl of Flickr; this turned out to be relatively easy. The two graphs (the Kaggle graph and our Flickr crawl), were 95% similar, as we were later able to determine. The difference is primarily due to Flickr users adding and deleting contacts between Kaggle’s crawl and ours. Armed with the auxiliary data, we set about the task of matching up the two graphs based on the structure. To clarify: our goal was to map the nodes in the Kaggle training and test dataset to real Flickr nodes. That would allow us to simply look up the pairs of nodes in the test set in the Flickr graph to see whether or not the edge exists.
De-anonymization. Our effort validated the broad strategy in my paper with Shmatikov, which consists of two steps: “seed finding” and “propagation.” In the former step we somehow de-anonymize a small number of nodes; in the latter step we use these as “anchors” to propagate the de-anonymization to more and more nodes. In this step the algorithm feeds on its own output.
Let me first describe propagation because it is simpler.[2] As the algorithm progresses, it maintains a (partial) mapping between the nodes in the true Flickr graph and the Kaggle graph. We iteratively try to extend the mapping as follows: pick an arbitrary as-yet-unmapped node in the Kaggle graph, find the “most similar” node in the Flickr graph, and if they are “sufficiently similar,” they get mapped to each other.
Similarity between a Kaggle node and a Flickr node is defined as cosine similarity between the already-mapped neighbors of the Kaggle node and the already-mapped neighbors of the Flickr node (nodes mapped to each other are treated as identical for the purpose of cosine comparison).
 In the diagram, the blue nodes have already been mapped. The similarity between A and B is 2 / (√3·√3) = ⅔. Whether or not edges exist between A and A’ or B and B’ is irrelevant.
In the diagram, the blue nodes have already been mapped. The similarity between A and B is 2 / (√3·√3) = ⅔. Whether or not edges exist between A and A’ or B and B’ is irrelevant.
There are many heuristics that go into the “sufficiently similar” criterion, which are described in our paper. Due to the high percentage of common edges between the graphs, we were able to use a relatively pure form of the propagation algorithm; the one my paper with Shmatikov, in contast, was filled with lots more messy heuristics.
Those elusive seeds. Seed identification was far more challenging. In the earlier paper, we didn’t do seed identification on real graphs; we only showed it possible under certain models for error in auxiliary information. We used a “pattern-search” technique, as did the Backstrom et al paper uses a similar approach. It wasn’t clear whether this method would work, for reasons I won’t go into.
So we developed a new technique based on “combinatorial optimization.” At a high level, this means that instead of finding seeds one by one, we try to find them all at once! The first step is to find a set of k (we used k=20) nodes in the Kaggle graph and k nodes in our Flickr graph that are likely to correspond to each other (in some order); the next step is to find this correspondence.
The latter step is the hard one, and basically involves solving an NP-hard problem of finding a permutation that minimizes a certain weighting function. During the contest I basically stared at this page of numbers for a couple of hours, and then wrote down the mapping, which to my great relief turned out to be correct! But later we were able to show how to solve it in an automated and scalable fashion using simulated annealing, a well-known technique to approximately solve NP-hard problems for small enough problem sizes. This method is one of the main research contributions in our paper.
After carrying out seed identification, and then propagation, we had de-anonymized about 65% of the edges in the contest test set and the accuracy was about 95%. The main reason we didn’t succeed on the other third of the edges was that one or both the nodes had a very small number of contacts/friends, resulting in too little information to de-anonymize. Our task was far from over: combining de-anonymization with regular link prediction also involved nontrivial research insights, for which I will again refer you to the relevant section of the paper.
Lessons. The main question that our work raises is where this leaves us with respect to future machine-learning contests. One necessary step that would help a lot is to amend contest rules to prohibit de-anonymization and to require source code submission for human verification, but as we explain in the paper:
The loophole in this approach is the possibility of overfitting. While source-code verification would undoubtedly catch a contestant who achieved their results using de-anonymization alone, the more realistic threat is that of de-anonymization being used to bridge a small gap. In this scenario, a machine learning algorithm would be trained on the test set, the correct results having been obtained via de-anonymization. Since successful [machine learning] solutions are composites of numerous algorithms, and consequently have a huge number of parameters, it should be possible to conceal a significant amount of overfitting in this manner.
As with the privacy question, there are no easy answers. It has been over a decade since Latanya Sweeney’s work provided the first dramatic demonstration of the privacy problems with data anonymization; we still aren’t close to fixing things. I foresee a rocky road ahead for machine-learning contests as well. I expect I will have more to say about this topic on this blog; stay tuned.
[1] Amusingly, it was a whole year after that before anyone paid any attention to the privacy claims in that paper.
[2] The description is from my post on the Kaggle forum which also contains a few additional details.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
A Cryptographic Approach to Location Privacy
I have a new paper “Location Privacy via Private Proximity Testing” with Narendran Thiagarajan, Mugdha Lakhani, Mike Hamburg and Dan Boneh. Mike spoke about it at NDSS earlier this week, where it won a distinguished paper award.
What is Private Proximity Testing?
The premise behind our paper is simple: smartphone-based location services today require you to reveal your location to the service provider. Is it possible to have at least a limited set of location services without revealing your location?
One might ask why this is useful since your carrier tracks your location anyway. The answer is that while you might (grudgingly) trust your carrier with your location, your might not trust Facebook, Loopt, Foursquare, or whatever the newest location startup is.
We show that it is indeed possible to provide location functionality in a private manner: specifically, it is possible to do proximity testing with privacy. What this means is that a pair of friends will be automatically notified when they are nearby, but otherwise no information about their locations will be revealed to anyone.
This is a strong notion of privacy—not only does the service provider never get to learn your location, your friends don’t learn your location either except that when you are nearby, the learn the fact that you’re nearby. This is appropriate given the loose notion of ‘friend’ in online social networking.
Note that our concept is a natural fit for the background-service model, where the location app sits in the background and constantly monitors your location, whereas most commercial apps today use the check-in model, where explicit user action is required to transmit data or provide service. We will return to this point later.
Tessellations

Three overlapping hexagonal grids. A blue grid cell is highlighted
The way we detect when two friends are nearby is by dividing the plane[1] into a system of 3 overlapping hexagonal grids. Cryptographic protocols for “Private Equality Testing” allow a pair of users to compare if they are within the same grid cell, but otherwise reveal nothing. By repeating this protocol for each of the 3 grids, they learn if they are close to each other.
For details of how this works, and why simpler methods won’t work, you’ll have to read the paper.
[1] The curvature of the Earth can be ignored since the distances across which our app is intended to work are small.
Theory and Practice
My favorite aspect of this paper is that our research spans the spectrum from math to implementation. This is something that Stanford CS is especially good at.
On the theory front, our contributions were mainly new Private Equality Testing algorithms. Not quite brand-new, but optimizations of existing algorithms. At one point we were really excited about having come up with an algorithm based on an improvement to an arcane complexity-theoretic result called Barrington’s theorem, and were looking forward to what would almost certainly have been the first time ever that it had been implemented in actual software! Unfortunately we later found a more efficient algorithm that used much more prosaic math.
Location tags: because every point in space-time has a fingerprint
On to a completely different part of the paper. Think about all the electromagnetic waves and signals floating around us all the time, varying from point to point, constantly changing and carrying data—GPS, GSM, Bluetooth, WiFi, and many, many others. By extracting entropy from these signals, everyone at a given place at a given time has a shared secret—unpredictable if you’re not at the right place at the right time. Think of the possibilities!
We call these shared secrets location tags. The catch is that the tags extracted by two people are largely equal, but not exactly. What we show in the paper is a cryptographic version of error correction that enables using these approximately-equal secrets as if they were exactly equal. Location tags were introduced by my co-author Boneh and others in an earlier paper; we adapted their work to enable the idea of a shared secret for each time and place.
There are many possible uses for location tags. We use them to ensure that it isn’t possible to spoof your location and try to “cheat.” This is a big problem for Foursquare for example. Here’s another possible use: let’s say a conference wants to have an encrypted chatroom. Instead of handing out keys or passwords—insecure and inconvenient—how about automatically extracting the key from the audio of the conference room! This restricts access to those in the room, and also has forward secrecy, since there are no long-term keys.
This part of our paper is theoretical. We did the math but didn’t build it. The main limitation is the ability of phone hardware to extract location tags. Currently the main viable method is using WiFi traffic; we showed experimentally that robust tags can be extracted within a few seconds. We’re confident that as hardware improves, location tag-based cryptography will become more practical.
Adoption. We talked to both Google and Facebook about adopting our technology in their products. Their responses were lukewarm at best. One barrier seemed to be that current services are committed to the check-in model, whereas our method only works in the background-service model. Ironically, I believe that a major reason the check-in model won (even though Loopt, which took the early lead, was a background app), was privacy—users weren’t comfortable broadcasting their location to their service provider and their friends all the time.
While that was somewhat disappointing, the applicability of our research extends well beyond the consumer web, for example in enterprise or even military settings. Imagine a product manager who wants to track who is attending which events, but wants to guarantee employees that no other information is being collected. Our app is a perfect fit for this scenario.
We’re happy that our ideas are out there, and are always looking to talk to people in the industry who might be interested in making our concept and prototype a reality.
Special thanks to students Frank Wang and Kina Winoto for helping us with the implementation.
There are more blog posts in the pipeline related to this paper. For one, I learnt a lot about the challenges of trying to get crypto adopted in the real world. For another, I’m very excited about a sub-project of this paper called SocialKeys that aims to make encryption transparent, largely eliminating the idea of key management from the user perspective. Stay tuned!
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Ubercookies Part 2: History Stealing meets the Social Web
Recap. In the previous article I introduced ubercookies — techniques that websites can use to de-anonymize visitors. I discussed a recent paper that shows how to use history stealing along with social network group membership information to find the visitor’s identity, and I promised a stronger variant of the attack.
The observation that led me to the attack I’m going to describe is simple: social networking isn’t just about social networks — the whole web has gone social. It’s a view that you quickly internalize if you spend any time hanging out with Silicon Valley web entrepreneurs :-)
Let’s break the underlying principle of the identity-stealing attack down to its essence:
A user leaves a footprint whenever their interaction with a specific web page is recorded publicly.
De-anonymization happens when the attacker can tie these footprints together into “trails” that can then be correlated with the user’s browser history. Efficiently querying the history to identify multiple points on the trail is a challenging problem to solve, but in principle de-anonymization is possible as long as the user’s actions on different web pages happen under the same identity.
Footprints can be tied together into trails as long as all the interactions happen under the same identity. There is no need for the interactions to be on the same website.
There are two major ways in which you can interact with arbitrary websites under a unified identity, both of which are defining principles of the social web. The first is federated identity, which means you can use the same identity provider wherever you go. This is achieved through OpenID and similar mechanisms like Facebook Connect. The second is social sharing: whenever you find something interesting anywhere on the web, you feed it back to your social network.
Now let’s examine the different types of interactions in more detail.
A taxonomy of interaction on the social web.
0. The pre-social web had no social networks and no delegated identity mechanism (except for the failed attempt by Microsoft called Passport). Users created new identities on each website, authenticated via site-specific usernames and passwords to each site separately. The footprints on different sites cannot be tied together; for practical purposes there are no footprints.

1. Social networks: affiliation. In social networks, users interact with social objects and leave footprints when the actions are public. The key type of interaction that is useful for de-anonymization is the expression of affiliation: this refers to not just the group memberships studied in the recent Wondracek et al. paper, but also includes
- memberships of fan pages on Facebook
- “interests” on Livejournal
- follow relationships and plain old friend relationships on Twitter and other public social networks
- subscriptions to Youtube channels
and so on.
All of these interactions, albeit very different from the user perspective, are fundamentally the same concept:
- you “add yourself” to or affiliate yourself with some object on a social network
- this action can be publicly observed
- you almost certainly visited a URL that identifies the object before adding it.

2. The social web: sharing. When you find a page you like — any page at all — you can import it or “share” it to your social stream, on Facebook, Twitter, Google Buzz, or a social bookmarking site like Delicious. The URL of the page is almost certainly in your history, and as long as your social stream is public, your interaction was recorded publicly.

3. The social web: federated identity. When you’re reading a blog post or article on the social web, you can typically comment on it, “like” it, favorite it, rate it, etc. You do all this under your Facebook, Google or other unified identity. These actions are often public and when they are, your footprint is left on the page.
A taxonomy of attacks
The three types of social interactions above give rise to a neat taxonomy of attacks. They involve progressively easier backend processing and progressively more sophisticated history search techniques on the front end. But the execution time on the front-end doesn’t increase, so it is a net win. Here’s a table:
| Type of interaction |
Backend processing |
Type of history URL |
Location of footprint |
| Affiliation | Crawling of social network | Object in a social network | In the social network |
| Sharing | Syndication of social stream(s) from social network | Any page | In the social network |
| Federated identity | None; optional crawling | Any page | On the page |
.
1. Better use of affiliation information. The Wondracek et al. paper makes use of only group membership. One natural reason to choose groups is that there are many groups that are large, with thousands of members, so it gives us a reasonably high chance that by throwing darts in the browser history we will actually hit a few groups that the user has visited. On the other hand, if we try to use the Facebook friend list, for example, hoping to find one of the user’s friends by random chance, it probably won’t work because most users have only a few hundred friends.
But wait: many Twitter users have thousands or even millions of followers. These are known as “hubs” in network theory. Clearly, the attack will work for any kind of hubs that have predictable URLs, and users on Twitter have even more predictable URLs (twitter.com/username) than groups on various networks. The attack will also work using Youtube favorites (which show up by default on the user’s public profile or channel page) and whatever other types of affiliation we might choose to exploit, as long as there are “hubs” — nodes in the graph with high degree. Already we can see that many more websites are vulnerable than the authors envisaged.
2. Syndicating the social stream: my Delicious experiment.
The interesting thing about the social stream is that you can syndicate the stream of interactions, rather than crawling. The reasons why syndication is much easier than crawling are more practical than theoretical. First, syndicated data is intended to be machine readable, and is therefore smaller as well as easier to parse compared to scraping web pages. Second, and more importantly, you might be to get a feed of the entire site-wide activity instead of syndicating each user’s activity stream separately. Delicious allows global syndication; Twitter plans to open this “firehose” feature to all developers soon.
Another advantage of the social stream is that everything is timestamped, so you can limit yourself to recent interactions, which are more likely to be in the user’s history.
Using the delicious.com dataset made available by DAI-labor (a log of all bookmarking activity on delicious.com over several years), I did a simulated experiment using 3 months worth of data: assuming that users keep their history around for 3 months, do in fact visit every link they post on delicious, how many users would a hypothetical history stealing attack be able to identify? I had a pretty good success rate: about 60% of the users who had shared at least 2 links in the 3-month period, or about 300,000 users. This takes at most 4000-5000 Javascript history queries.
Needless to say, once Twitter opens up its firehose, Twitter users (who are far more numerous than delicious users) would also be susceptible to the same technique.
This attack is not possible to fix via server-side URL randomization. It can also be made to work using Facebook, Google Buzz, and other sharing platforms, although the backend processing required won’t be as trivial (but probably no harder than in the original attack.)
3. A somewhat random walk through the history park.
And now for an approach that potentially requires no backend data collection, although it is speculative and I can’t guess what the success rate would be. The attack proceeds in several steps:
- Identify the user’s interests by testing if they’ve visited various popular topic-specific sites. Pick one of the user’s favorite topics. Incidentally, a commenter on my previous post notes he is building exactly this capability using topic pages on Wikipedia, also with the goal of de-anonymization!
- Grab a list of the top blogs on the topic you picked from one of the blog directories. Query the history to see which of these blogs the user reads frequently. It is even possible to estimate the level of interest in a blogs by looking at the fraction of the top/recent posts from that blog that the user has visited. Pick a blog that the user seems to visit regularly.
- Look for evidence of the user leaving comments on posts. For example, on Blogger, the comment page for a post has the URL http://www.blogger.com/comment.g?blogID=<blogid>&postID=<postid>.
- Once you find a couple of posts where it looks like the user made a comment, scrape the list of people who commented on it, find the intersection. (Even a single comment might suffice; as long as you have a list of candidates, you easily verify if it’s one of them by testing user-specific URLs. More below.)
- Depending on the blogging platform, you might even be able to deduce that the user responded (or intended to respond) to a specific comment. For example, On wordpress you have the pattern http://<blogname>.wordpress.com/<postname>/?replytocom=<commentid>#respond. If you get lucky and find one of those patterns, that makes things even easier.
If at first you don’t succeed, pick a different blog and repeat.
I suspect that the most practical method would be to use a syndicated activity stream from a social network, but also to use the heuristics presented above to more efficiently search through the history.
Epilogue: Identity.
Not only has there been a movement towards a small number of identity providers on the web, there are many aggregators out there that have sprung up in order to automatically find the connections between identities across the different identity providers, and also connect online identities to physical-world databases. As Pete Warden notes:
One of the least-understood developments of the last few years is the growth of databases of personal information linked to email addresses. Rapleaf is probably the leader in this field, but even Flickr lets companies search their API for users based on an email address.
I ran my email address through his demo script and it is quite clear that virtually all of my online identities have been linked together. This is getting to be the norm; as a consequence, once an attacker gets any kind of handle on you, they can go “identity hopping” and find out a whole lot more about you.
This is also the reason that once the attacker can make a reasonable guess at the visitor’s identity, it’s easy to verify the guess. Not only can they look for user-specific URLs in your history to confirm the guess (described in detail in the Wondracek et al. paper), but all your social streams on other sites can also be combined with your history to corroborate your identity.
Up next in the Ubercookies series: So that’s pretty bad. But it’s going to get worse before it can get better :-) In the next article, I will describe an entirely different attack strategy to get at your identity by exploiting a bug in a specific identity provider’s platform.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Cookies, Supercookies and Ubercookies: Stealing the Identity of Web Visitors
 Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Cookies. Most people are aware that their web browsing activity over time and across sites can be tracked using cookies. When you are being tracked, it can be deduced that the same person visited certain sites at certain times, but the sites doing the tracking don’t know who you are, i.e., you name, etc., unless you choose to tell them in some way, such as by logging in.
Cookies are easy to delete, and so there’s been a big impetus in the Internet advertising industry to discover and deploy more robust tracking mechanisms.
Supercookies. You may surprised to find just how helpless a user is against a site (or more usually, a network of sites) that is truly determined to track them. There are Flash cookies, much harder to delete, some of which respawn the regular HTTP cookies that you delete. The EFF’s Panopticlick project demonstrates many “browser fingerprinting” methods which are more sophisticated. (Jonathan Mayer’s senior thesis contained a smaller-scale demonstration of some of those techniques).
A major underlying reason for a lot of these problems is that any browser feature that allows a website to store “state” on the client can be abused for tracking, and there are a bewildering variety of these. There is a great analysis in a paper by my Stanford colleagues. One of the points they make is that co-operative tracking by websites is essentially impossible to defend against.
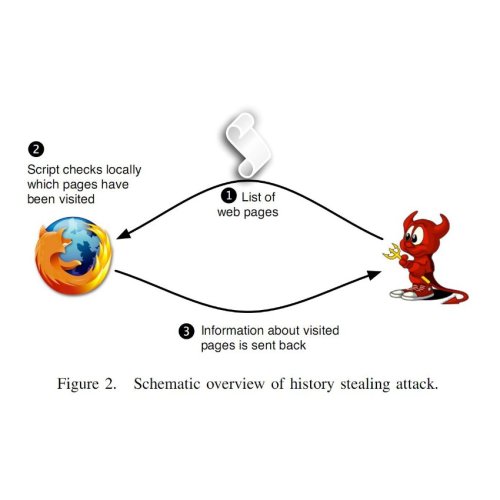
Ubercookies: history stealing. Now let’s get to the scary stuff: uncovering identity. History stealing or history sniffing is an unintended consequence of the way the web is designed; it allows a website to learn which URLs you’ve been to. While a site can’t simply ask your browser for a list of visited URLs, it can ask “yes/no” questions and your browser will faithfully respond. The most common way of doing this is by injecting invisible links into the page using Javascript and exploiting the fact that the CSS link color attribute depends on whether the link has been visited or not.
History stealing has been known for a decade, and browser vendors have failed to fix it because it cannot be fixed without sacrificing some useful functionality (the crude way is to turn off visited link coloring altogether; a subtler solution is SafeHistory). Increasingly worse consequences have been discovered over the years: for example, a malicious site can learn which bank you use and customize a phishing page accordingly. But a paper (full text, PDF) coming out at this year’s IEEE S&P conference at Oakland takes it to a new level.
Identity. Let’s pause for a second and think about what finding your identity means. In the modern, social web, social network accounts have become our de-facto online identities, and most people reveal their name and at least some other real-world information about ourselves on our profiles. So if the attacker can discover the URL of your social network profile, we can agree that he has identified you for all practical purposes. And the new paper shows how to do just that.
The attack relies on the following observations:
- Almost all social networking sites have some kind of “group” functionality: users can add themselves to groups.
- Users typically add themselves to multiple groups, at least some of which are public.
- Group affiliations, just like your movie-watching history and many other types of attributes, are sufficient to fingerprint a user. There’s a high chance there’s no one else who belongs to the same set of groups that you do (or is even close). [Aside: I used this fact to show that Lending Club data can be de-anonymized.]
- Users who belong to a group are likely to visit group-specific URLs that are predictable.
Put the above facts together, and the attack emerges: the attacker (an arbitrary website you visit, without the co-operation of whichever social network is used as an attack enabler) uses history stealing to test a bunch of group-related URLs one by one until he finds a few (public) groups that the anonymous user probably belongs to. The attacker has already crawled the social network, and therefore knows which user belongs to which groups. Now he puts two and two together: using the list of groups he got from the browser, he does a search on the backend to find the (usually unique) user who belongs to all those groups.
Needless to say, this is a somewhat simplified description. The algorithm can be easily modified so that it will work even if some of the groups have disappeared from your history (say because you clear it once in a while) or if you’ve visited groups you’re not a member of. The authors demonstrated that the attack with real users on the Xing network, and also showed theoretically that it is feasible on a number of other social networks including Facebook and Myspace. It takes a few thousand Javascript queries and runs in a few seconds on modern browsers, which makes it pretty much surreptitious.
Fallout. There are only two ways to try to fix this. The first is for all the social networking sites to change their URL patterns by randomizing them so that point 4 above (predictable URL identifying that you belong to a group) is no longer true. The second is for all the browser vendors to fix their browsers so that history stealing is no longer possible.
The authors contacted several of the social networks; Xing quickly implemented the URL randomization fix, which I find surprising and impressive. Ultimately, however, Xing’s move will probably be no more than a nice gesture, for the following reason.
Over the last few days, I have been working on a stronger version of this attack which:
- can make use of every URL in the browser history to try and identify the user. This means that server-side fixes are not possible, because literally every site on the web would need to implement randomization.
- avoids the costly crawling step, further lowering the bar to executing the attack.
That leaves browser-based fixes for history stealing, which hasn’t happened in the 10 years that the problem has been known. Will browsers vendors finally accept the functionality hit and deal with the problem? We can hope so, but it remains to be seen.
In the next article, I will describe the stronger attack and also explain in more detail why your profile page on almost any website is a very strong identifier.
Thanks to Adam Bossy for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Privacy is not Access Control (But then what is it?)
In my previous article on the Google Buzz fiasco, I pointed out that the privacy problems were exacerbated by the fact that the user interface was created by programmers. In this post I will elaborate on that theme and provide some constructive advice on privacy-conscious design, especially for social networking.
The problem I’m addressing is that as far as computer scientists and computer programmers are concerned, privacy is a question of access control, i.e., who is allowed to look at what. Unfortunately, in the real world, that is only a tiny part of what privacy is about. Here are three examples to make my point:
1. Dummy cameras. Consider a thought experiment: suppose the government installed a bunch of cameras all over a public park along with prominent signs announcing 24×7 surveillance. The catch, however, is that the cameras have not been turned on. Has anyone’s privacy been violated?
From the computer science perspective, the answer is no, because no one is actually being observed, nothing is being recorded and no data is being generated. But common sense tells us that something is wrong with that answer. The cameras cause people considerable discomfort. The surveillance, real or imaginary, changes their behavior.
This hypothetical scenario is adapted from Ryan Calo’s paper, which analyzes in detail the “sensation of being observed.”
2. Aggregation changes the equation. Remember the uproar when Facebook released News Feed? No new information was revealed to your friends that wasn’t accessible to them before; it was just that the News Feed made it dramatically easier to observe all your activities on the site.
Of course, it goes both ways: the technology in turn changed people’s expectations; it is now hard to imagine not having a feed-like system, whether on Facebook or another social network. Nevertheless, I often see people putting something into their profile, deciding a few moments later that they didn’t want to share it after all, and realizing that it was too late because the information has already been broadcast to their friends.
3. Everyone-but-X access control, which I described in an earlier article, shows in a direct way how access control fails to capture privacy requirements. From the traditional CS security perspective, the ability for a user to make something visible to “everyone but X” is meaningless: X can always create a fake account to get around it.
But a use-case should hopefully immediately convince you that everyone-but-X is a good idea: your sibling is on your friends list and you want to post about your sex life. It’s not that you want to prevent X from having access to your post, but rather that both of you prefer that X didn’t have access to it.
Access control is not the goal of privacy design. It is at best one of many tools. Rather, human behavior is key. The dummy cameras were bad because they affected the behavior of people in a detrimental way. News feed was bad because it introduced major new privacy consequences for the behaviors that people were accustomed to on the site. (However, I would argue that the dramatic increase in usefulness trumped the privacy drawbacks.) Everyone-but-X privacy is good because it allows people to carry over to the online setting behaviors that they are used to in the real world.
It is impossible to fully analyze the privacy consequences of a design decision without studying its impact on actual user behavior. There is no theoretical framework to ensure that a design decision is safe — user testing is essential. Going back to Google Buzz, a beta period or a more gradually phased roll-out would have undoubtedly been better.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Google Buzz, Social Norms and Privacy
Another day, another privacy backlash — this time with Google Buzz. What’s new? Lots, as it turns out.
There are many minor ways in which Google Buzz fails, both with regard to privacy and otherwise. For example, I’ve been posting my Buzz updates publicly because the user interface for posting it to a restricted group is horribly clunky. (Post only to my followers? What’s the point of that, when anyone can start following me?! Make it easy to post to a group that I have control over!)
But the major privacy SNAFU, as you’ve probably heard, is auto-follow. Google automatically makes public a list of the top 25 or so people you’ve corresponded with in Gmail or Google talk. Worse, the button to turn this “feature” off resides in your Google-wide profile, making it unnecessarily hard to find because it isn’t within the Buzz interface itself.
This is a classic example of what happens when the user interface is created by programmers instead of designers, a recurring problem for Google. Programmers partition features in a way that fits the computer’s natural data model, rather than the user’s natural mental model.
But getting back to privacy, it is a certainty in a statistical sense that Google outed a few affairs and other secret relationships. For even if you were yourself savvy enough to turn off the public display of your top correspondents, there’s a good chance the other party wasn’t, and might not have turned it off on their end.
When I enabled Buzz and realized what had happened, something changed for me in my head. I’d always regarded email and chat as a private medium. But that’s not true any more; Google forced me to discard my earlier expectations. Even if Google apologizes and retracts auto-follow (not that I think that’s likely), the way I view email has permanently changed, because I can’t be sure that it won’t happen again. I lost some of the privacy expectation that I had of not only Google’s services, but of email and chat in general, albeit to a lesser extent.
What I’ve tried to do in the preceding paragraphs is show in a step-by-step manner how Google’s move changed social norms. The larger players like Google and Microsoft have been very conservative when it comes to privacy, unlike upstarts like Facebook. So why did Google enable auto-follow? By all accounts, their hand was forced: they needed a social network to compete with Facebook and Twitter. Given the head-start that their competitors have, the only real way to compete was to drag their users into participating.
Google ended up changing society’s norms in a detrimental way in order to meet their business objectives. This has become a recurring theme (c.f. the section on Facebook in that article). I don’t think there is any possibility of putting the genie back in the bottle; this trend will only continue. This time it was about who I email; soon my expectations about the contents of emails themselves will probably change.
I believe that in the long run, the only “stable equilibrium” of privacy norms, as it were, would be for everyone to simply assume that everything they type into a computer will be publicly visible either instantly or at some point in the future, outside their control. That is not necessarily as terrible as it may seem. Nonetheless, society will take a long time to get there. Until then, the best we can do is push back against intrusions as much as possible, delaying the inevitable, giving ourselves enough time to adapt.
Do your part to fight back against auto-follow. Let Google know how you feel. Blog about it or leave a comment.
Updates
- A New York Times blogger picked up the controversy.
- Joe Bonneau has an analysis of users’ confused reactions.
- Google has announced that it is rolling out some user-interface changes in response to the feedback. That is better than before, but the default is still public auto-follow.
- The horror stories due to auto-follow have begun.
- I have a new article with advice on privacy-conscious design.
- Google decided to nix auto-follow after all! Awesome.
Thanks to Joe Bonneau for reviewing a draft of this article.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Livejournal Done Right: The Case for a Social Network with Built-in Privacy
Is it time to give up on privacy in social networking? I argue that the exact opposite is true. Impatient readers can skip to the bullet-point summary at the end.
Based on my work on de-anonymizing social networks with Shmatikov, and other research such as Bonneau & Preibusch’s survey of the dismal state of privacy in social networks, many people have concluded that it is time to give up on social networking privacy. In my opinion, this couldn’t be farther from the truth.
Being a hard-headed pragmatist (at least by the lax standards of academia (-:), I will make the case that there is a market for a social networking site designed from the ground-up with privacy in mind, as opposed to privacy being tagged on piecemeal in reaction to PR incidents.
It would seem that a good place to start would be to look at existing social networks with designed-in privacy, and see how they have fared. Unfortunately, researchers are still hammering out exactly what that would look like, and there are no real examples in the wild. In fact, part of the reason for this post is to flesh out some principles for designed-in privacy. So I will use a definition based on privacy outcomes instead:
The privacy strength of a social network is the extent to which its users share sensitive information with one another.
Viewed from this perspective, there is only one widely-used social network (at least in the U.S.) that has strong privacy, one that stands out from all the rest: LiveJournal.
While Facebook’s privacy controls are more technologically sophisticated, there is little doubt that far more revelations of a private nature are made on LiveJournal. This discrepancy is central to the point I want to make: achieving privacy is not just about technological decisions.
There is one overarching reason for LiveJournal’s privacy success: They make it (relatively) easy for users to communicate their mental access control rules to the system. In my opinion, this should the the single most important privacy goal of a social network; the technical problem of implementing those access control rules is secondary and much easier.
On Livejournal, the goal is achieved largely due to two normative user behaviors:
- Friending is not indiscriminate (see below).
- Users actually use friend lists for access control.
Herding users into these behaviors is far from easy, and LiveJournal stumbled there through a variety of disparate design decisions, some wise, some not so wise, some that worked against their interest in the long run, and some downright bizarre.
- Friendship is not mutual. While in practice over 90% of friendships are reciprocated, the difference crucially captures the asymmetric nature of trust.
- The site is insular — it plays poorly with search engines; RSS support has been way behind other blog platforms.
- Privacy settings are highly visible, rather than being tucked away in a configuration page. Just a couple of examples:
- there is a privacy-level dropdown menu on the post-new-entry page.
- when you add a friend, you are prompted to add them to one or more friend lists.
- Weak identity. The site does not require or encourage a user to use their real name. Many users choose to hide their real-life identity from everyone except their friend-list.
- Livejournal doesn’t inform users when they are friended. From the privacy perspective, this is a feature(!) rather than a bug — it decreases the embarrassment of an unreciprocated friending by letting both users pretend that the user who was friended didn’t notice (even though most regular users use external tools to receive such notifications.). The social norms around friending are in general far more complex than on Facebook, and there is a paper that analyzes them.
As you may have gathered from the above, social norms have a huge impact on the privacy outcome of a site; this explains both why privacy is about more than technology, as well as why privacy can never be achieved as an afterthought — because norms that have evolved can hardly ever be undone. Regrettably, but unsurprisingly, the CS literature on social network privacy has been largely blind to this aspect. (Fortunately, economists, philosophers, some hard-to-categorize researchers, and needless to say, sociologists and legal scholars have been researching social network privacy.)
Returning to my main thesis, I believe that privacy has been the central selling-point of Livejournal, even though it was never marketed to users in those terms. The privacy-centric view explains why the userbase is so notoriously vocal, why the site is able to get users to pay, why they have a huge fanfic community, much of it illegal, and why Livejournal users find it impossible to migrate to other mainstream social networks, which all lack any semblance of the privacy norms that exist on Livejournal.
Livejournal is dying, at least in the U.S., which I believe is largely due to erratic design decisions. While the decay of the site has been obvious to most users (who have seen the frequency of new posts basically fall off a cliff in the last few months), I don’t have concrete data on post frequency. Fortunately, it is not essential to the point I’m making, which is that Livejournal got a few things right but also made a lot of mistakes. We now know a lot more about privacy by design in social networks than we did a decade ago, and it is possible to do much better by starting from scratch. There is now a huge unfulfilled need in the market for someone to take a crack at.
Finally, I’m going to throw in two examples of design decisions that Livejournal (or any other network) never implemented but I believe would be hugely beneficial in achieving positive privacy outcomes:
“Everyone-but-X” access control. This is an example of a whole class of access control primitives that make no sense from the traditional computer science security perspective. If an item is visible to every logged-in user except X, X can always create a fake (“sybil”) account to get around it.
However, let me give you one simple example that I hope will immediately convince you that everyone-but-X is a good idea: your sibling is on your friends list and you want to post about your sex life. It’s not so much that you want to prevent X from having access to your post, but rather that both of you prefer that X didn’t have access to it. The relationship is not adversarial. Extrapolating a little bit, most users can benefit from everyone-but-X privacy in one context or another, but amazingly, no social network has thought of it.
The problem here is that traditional CS security theory lacks even the vocabulary to express what’s going on here. Fortunately, researchers are wising up to this, and a new paper that will be presented at ESORICS later this month argues that we need a new access control model to reason about social network privacy, and presents one that is based on Facebook (I really like this paper).
Stupidly easy friend lists. Having to manually manage friend-lists puts it beyond the patience level of the average user, and offers no hope of getting users who already have several hundred uncategorized friends to start categorizing. But technology can help: I’ve written about automated friend-list clustering and classification before.
Summary. As promised, in bullet points:
- Livejournal is the only major social network whose users regularly share highly private material.
- Livejournal achieved this largely because they made it easy for users to communicate their mental access control rules to the system.
- To habituate users into doing this, social norms are crucial. They matter more than technology in affecting privacy outcomes.
- Designing privacy is therefore largely about building the right tools to get the right social norms to evolve.
- Livejournal doesn’t seem to have a bright future. Besides, they made many mistakes and never realized their full potential.
- Therefore, privacy-conscious users form a large and currently severely underserved segment of the social networking audience.
- The lessons of Livejournal and recent research can help us design privacy effectively from the ground up. The time is right, and the market is ripe.
Final note. I will be presenting the gist of this essay (preceded by a survey of the academic attempts at privacy by design) at the Social Networking Security Workshop at Stanford this Friday.
Some of the ideas in this post were inspired by these essays by Matthew Skala.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
De-anonymizing Social Networks
Our social networks paper is finally officially out! It will be appearing at this year’s IEEE S&P (Oakland).
Please read the FAQ about the paper.
Abstract:
Operators of online social networks are increasingly sharing potentially sensitive information about users and their relationships with advertisers, application developers, and data-mining researchers. Privacy is typically protected by anonymization, i.e., removing names, addresses, etc.
We present a framework for analyzing privacy and anonymity in social networks and develop a new re-identification algorithm targeting anonymized social-network graphs. To demonstrate its effectiveness on real-world networks, we show that a third of the users who can be verified to have accounts on both Twitter, a popular microblogging service, and Flickr, an online photo-sharing site, can be re-identified in the anonymous Twitter graph with only a 12% error rate.
Our de-anonymization algorithm is based purely on the network topology, does not require creation of a large number of dummy “sybil” nodes, is robust to noise and all existing defenses, and works even when the overlap between the target network and the adversary’s auxiliary information is small.
The HTML version was produced using my Project Luther software, which in my opinion produces much prettier output than anything else (especially math formulas). Another big benefit is the handling of citations: it automatically searches various bibliographic databases and adds abstract/bibtex/download links and even finds and adds links to author homepages in the bib entries.
I have never formally announced or released Luther; it needs more work before it can be generally usable, and my time is limited. Drop me a line if you’re interested in using it.
Social Network Analysis: Can Quantity Compensate for Quality?

Science magazine has labeled Christakis and Fowler the “dynamic duo”
Nicholas Christakis of Harvard and James Fowler of UC San Diego have produced a series of ground-breaking papers analyzing the spread of various traits in social networks: obesity, smoking, happiness, and most recently, in collaboration with John Cacioppo, loneliness. The Christakis-Fowler collaboration has now become well-known, but from a technical perspective, what was special about their work?
It turns out that they found a way to distinguish between the three reasons why people who are related in a social network are similar to each other.
- Homophily is the tendency of people to seek others who are alike. For example, most of us restrict our dates to smokers or non-smokers, mirroring our own behavior.
- Confounding is the phenomenon of related individuals developing a trait because of a (shared) environmental circumstance. For example, people living right next to a McDonald’s might all gradually become obese.
- Induction is the process of one individual passing a trait or behavior on to their friends, whether by active encouragement or by setting an example.
Clearly, only induction can cause a trait to actually spread in a social network. To distinguish between the three effects and to prove causality, according to the authors, the key is longitudinal data–data from the same individuals collected over a period of years or decades. All of the works cited above are based on the Framingham Heart Study. This corpus of data is ideally suited in several ways:
- It contains data from three generations of individuals.
- Very few of the participants (10 out of over 5,000) dropped out:
- The original study sample comprised the majority of the population of Framingham, which is (presumably) a somewhat closed social network.
This illustrates the traditional way of doing things, using carefully selected high-quality data. With the growth of online social networking websites, however, a radically different approach is gaining prominence. A good example is this Slate article that analyzes the recent “25 random things” Facebook meme using well-known epidemiological models, and concludes that marketers should “introduce a wide variety of schemes into the wild and pray like hell that one of them evolves into a virulent meme.” For a more academic/rigorous example, see the paper “Characterizing Social Cascades in Flickr” (pdf), which looks at how information disseminates through social links.
Many analogies come to mind when comparing the Old School to the New School: the Cathedral vs. the Bazaar, or Britannica vs. Wikipedia. Information in social networking sites is collected through a chaotic, organic, unsupervised process. The set of participants is entirely self-selected. Against these objections stands the indisputable fact that the process produces several orders of magnitude more data at a fraction of the cost.
Despite being only a few years old, online social network analysis has already produced deep insights: the work of Jon Kleinberg springs to mind. But will it supplant the traditional approach? I think so. My hypothesis is that with sufficiently powerful analytical methods, quantity can compensate for noise in the data. Don’t take my word for it: Harvard professor Gary King considers the availability of data from online social networks to be the “most significant turning point in the history of sociology.”
The amount and variety of social network data available to researchers, marketers, etc. is rapidly increasing; there is a detailed survey in my forthcoming paper (at IEEE S&P) on de-anonymizing social networks. In spite of the rather serious privacy concerns that are identified in the paper, the balance of business incentives appears to be towards more openness, and my prediction is that social networks will continue to move in that direction. Facebook alone has an incredible wealth of as-yet untapped data on information flow–recent the feed-focused redesign instantly transformed posted items, group memberships and fan pages into meme propagation mechanisms.
The new approach to social network analysis has benefits other than the quantity of data available. Equally important is the fact that users of social networking sites are not participating in a study; we get to observe their lives directly. The data is thus closer to reality. Furthermore, there is the possibility of studying the population actively rather than passively. For instance, if the goal is to study meme propagation, why not introduce memes into the population? This gives the researcher much greater control over the timing, point of introduction, and content of the memes being studied. Of course, this raises ethical and methodological questions, but they will be worked out in due course.
A third benefit of the new approach is that social network users often express themselves using free form text; utilized properly, this could yield much deeper data than making study participants check boxes on a Likert scale in response to canned questions (such as the now famous “How does it feel to be poor and black?“). The Flickr paper cited above analyzes the tags people use to describe pictures. With more technical sophistication, it should be possible, for example, to apply automated sentiment analysis to blog posts, tweets, etc. to determine how your opinion of a movie or book is influenced by those of your friends.
True, we don’t yet have data spanning several decades, but then things happen on a far faster timescale in the online world. There will always be research questions that fundamentally depend on studying aspects of the real world that are not replicable virtually. By and large, however, I believe the new approach is about to supplant the old. There is still a ways to go in terms of developing the techniques we need for analyzing massive, noisy datasets, but we will get there in a few short years. The Christakis-Fowler papers may soon exemplify the exception, rather than the rule, for social network analysis.
The Fallacy of Anonymous Institutions
The graph below is from the paper “Chains of affection: The structure of adolescent romantic and sexual networks.” The name of the school that the data was collected from is not revealed, and is given the working name “Jefferson High.” It is part of the National Longitudinal Study of Adolescent Health, containing very detailed health information on 100,000 high school students in 140 schools. In 12 of the schools, the entire sexual network was mapped out.
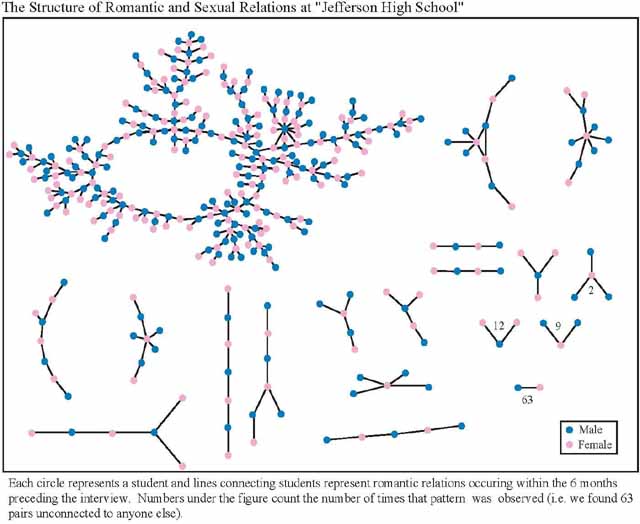
Clearly, the authors felt that concealing the identity of the school is important for protecting the privacy of the participants. It’s not hard to see why: firstly, the aggregate information presented in the study could by itself be unpleasant, especially facts about the prevalence of adolescent sexual activity in a conservative rural town (see below). Second, and more importantly, knowing the identity of the school can lead to further de-anonymization of the individuals in the network.
The graph above is rich enough that a few individuals can identify themselves purely based on the local information available to them, and thus learn things about their neighbors in the graph. A group of individuals getting together will have an even easier time of it. Furthermore, the actual paper provides a richer, temporally ordered version of the graph above.
But even strangers may benefit: depending on how well the temporal information in the sexual graph correlates with other temporal information that may be available, say from Facebook, de-anonymization might be possible with little or no co-operation from the subjects themselves. Soon, I will have more to say about research results on de-anonymizing graphs with loosely correlated external/auxiliary data.
Having established the privacy risk, let’s see how easy it is to re-identify Jefferson High. The authors give us these helpful clues:
“Jefferson High School” is an almost all-white high school of roughly 1000 students located in a mid-sized mid-western town. Jefferson High is the only public high school in the town. The town, “Jefferson City” is over an hour away by car from the nearest large city. Jefferson City is surrounded by beautiful countryside, home to many agricultural enterprises. The town itself is working class, although there remain some vestiges of better times. At one period, the town served as a resort for city dwellers, drawing an annual influx of summer visitors. This is no longer the case, and many of the old resort properties show signs of decay. The community is densely settled. At the time of our fieldwork, students were reacting to the deaths of two girls killed in an automobile accident.
Some further facts presented have high amusement value, and are equally useful for re-identification:
Jefferson students earn lower grades, are suspended more, feel less attached to school, and come from poorer families than those at comparable schools. They are more likely than students in other high schools to have trouble paying attention, have lower self-esteem, pray more, have fewer expectations about college, and are more likely to have a permanent tattoo. Compared to other students in large disproportionately white schools, adolescents in Jefferson High are more likely to drink until they are drunk. In schools of comparable race and size, on average 30% of 10th-12th grade students smoke cigarettes regularly, whereas in Jefferson, 36% of all 10th to 12th graders smoke. Drug use is moderate, comparable to national norms. Somewhat more than half of all students report having had sex, a rate comparable to the national average, and only slightly higher than observed for schools similar with respect to race and size. Nevertheless, if Jefferson is not Middletown, it looks like an awful lot like it. The adolescents at Jefferson High are pretty normal. In describing the events of the past year, many students report that there is absolutely nothing to do in Jefferson. For fun, students like to drive to the outskirts of town and get drunk. Jefferson is a close-knit insular predominantly working-class community which offers few activities for its youth.
A database of public schools in the U.S. is available for sale for $75, containing very detailed information about each school. I’m quite confident that the information in there is sufficient to re-identify Jefferson High.
This thesis of this blog that the amount of entropy required to de-anonymize an individual — 33 bits — is low enough that it doesn’t offer meaningful protection in most circumstances. Obviously, the argument applies even more strongly to the anonymity of a well-defined group of people.
Let’s be clear: the paper is from 1994; who slept with whom in high school is not a huge deal a decade and a half later. However, the problem is systemic, and IRBs (Institutional Review Boards) keep blithely approving releases of data with such nominal de-identification applied. The re-identification of the institutional affiliation of an entire population of a study is of more concern from the privacy perspective than the de-anonymization of individual identities: it needs to be done only once, and affects hundreds or thousands of individuals.
Recently, a group of researchers from the Berkman Center released a dataset of Facebook profile information from an entire cohort (the class of 2009) of college students from “an anonymous, northeastern American university.” It was promptly de-anonymized by Michael Zimmer, who revealed that it was Harvard College:
As I noted here, the press release and the public codebook for the dataset provided many clues to where the data came from: we know it is a northeastern US university, it is private, co-ed, and whose class of 2009 initially had 1640 students in it. A quick search for schools reveals there are only 7 private, co-ed colleges in New England states (CT, ME, MA, NH, R , VT) with total undergraduate populations between 5000 and 7500 students (a likely range if there were 1640 in the 2006 freshman class): Tufts University, Suffolk University, Yale University, University of Hartford, Quinnipiac University, Brown University, and Harvard College.
[…]
Finally, and perhaps most convincingly, only Harvard College offers the specific variety of the subjects’ majors that are listed in the codebook. While nearly all univerersities offer the common majors of “History”, “Chemistry” or “Economics”, one only needs to search for the more uniquely phrased majors to discover a shared home institution.
Another amusing example is a paper on mobile phone call graphs which attempts to keep the identity of an entire country secret. I found that the approximate population of the country reported in the paper together with the mobile phone penetration rate is sufficient to uniquely identify it.
Suppressing the identity of your study population has some privacy benefits: at least, it won’t show up in google searches. But relying on it for any kind of serious privacy protection would be foolish. Scrubbing an entire dataset or research paper of clues about the study population can be hard or impossible; further, a single study participant corroborating the published results or methodology might be sufficient for de-anonymization of the group. The only solution is therefore to assume that the identity of the study population will be discovered, and to try to ensure that individual identities will still be safe from re-identification.


{kind=link}