Posts tagged ‘history stealing’
History Stealing: It’s All Shades of Grey
Previous articles in this series showed that ‘Ubercookies’ can enable websites to learn the identity of any visitor by exploiting the ‘history stealing’ bug in web browsers, and presented different types of de-anonymization attacks. This article is all about the question, “but who is the adversary?”
 Good and evil. It is tempting for security researchers to think of the world in terms of good guys and bad guys — white hats and black hats. It is a view of the world that is probably hardwired into our brains, reflected everywhere from religious beliefs to Hollywood plots. But reality is more complex. Heroes are flawed, and the bad guys are not really evil. But enough with the moral lecture, let’s see how this pertains to history stealing and identity stealing.
Good and evil. It is tempting for security researchers to think of the world in terms of good guys and bad guys — white hats and black hats. It is a view of the world that is probably hardwired into our brains, reflected everywhere from religious beliefs to Hollywood plots. But reality is more complex. Heroes are flawed, and the bad guys are not really evil. But enough with the moral lecture, let’s see how this pertains to history stealing and identity stealing.
Black hat. I don’t need to say very much to convince you of the black-hat uses of learning your identity. I’ve already talked about how a phishing site that knows who you are can deliver a customized page that is dramatically more effective. Or imagine the potential for surveillance — with the cooperation of a single ad network, a Government can put a de-anonymization script on millions of websites and keep tabs on every click anyone makes. In fact, you only need to be de-anonymized once; regular tracking scripts will do the job after that.
Grey hat. But I want to argue here that the grey hat use case is far more likely/common than the black hat. For example, here’s an article arguing that websites should sniff their visitors’ history for a “better user experience.” The nonchalant way in which the author talks about exploiting a nasty bug and the lack of mention of any privacy concerns is both scary and amusing. In the comments section of that article you can find links to implementations. In fact there’s even a website selling history sniffing code that website owners can drop into their site.

Shades of grey. Consider a thought experiment. Suppose a website delivered a “better user experience” by sniffing your history, but didn’t send that information back to the server. Whatever web page customization happens is done purely in the browser using Javascript. Is that unethical? If you think it’s unethical, what about if the site popped up a box to get the user’s consent before doing so? Remember that 80% of users are going to click OK without understanding what the box says. At this point it’s looking pretty close to Adnostic, a paper/project I’ve been working on as a privacy enhancing tool.

My point here is not to defend history stealing. Rather, I hope I’ve convinced you that there’s a gentle gradient between white and black hat, at least in terms of intent, and that it’s hard to condemn someone unequivocally.
Incentive. For the most part, people who are using history sniffing “in the wild” are just trying to make an extra buck on their website through advertising. This is an extremely powerful incentive. You may not know how terrible ad targeting currently is on the web. You can find any number of horror stories like this one from Stack Overflow that says a million pageviews a day aren’t enough to pay one person part time. Anything that improves ad rates directly impacts the bottom line.
Now consider this:
The future of Internet ad targeting may lie in combining online and offline behavioral data. Several Web networks have already formed relationships with, or purchased, offline database companies. AdForce has a relationship with Experion, which has an offline database of about 120 million households in North America; likewise, DoubleClick purchased Abacus Direct, a shared catalog database with information on over 90 million U.S. households. 24/7 Media has also formed an alliance to link online and offline data.
Linking online and offline data means one thing: being able to not only track users online but also identify them. Hundreds of millions of dollars say this is going to happen one way or the other.
Some grey hat use cases. The “improved user experience” article linked above advocates history stealing for picking the right third party service providers to direct the user to by detecting which one they are already using – the right RSS reader, social bookmarking site, federated identity provider, mapping service, etc. But let’s talk about identity stealing instead of just history stealing.
Ad targeting, which I’ve already mentioned, can be improved not just by combining online with offline data but also by combining social network profile data with click tracking data. This may already be happening on some social networking sites, but identity stealing makes it possible to grab the user’s social network profile information no matter which site they’re on.
As I pointed out earlier, users are more likely to fall for phishing when the site addresses them by name. But this effect is not in any way specific to phishing. Any new site that wants to get users to try their service or to stick around longer can benefit from this technique to improve trust. Marketers have long absorbed Dale Carnegie’s wisdom that the sweetest word you can say to a person is their own name.
Grey hat is more worrisome than black hat. There are two reasons to worry about grey hat more than black hat. Every website that doesn’t have a reputation to lose is a potential user of grey hat techniques, whether history stealing or anything else. Second, grey hats are typically not using it for anything illegal (unlike phishers), which means you can’t use the law to shut them down.
This is a general thought that I want to leave computer security researchers. We are used to thinking of adversaries as malicious agents; this thinking has been reinforced by the fact that in the last decade or two, hacking went from harmless pranks to organized crime. But the nature of the adversary who exploits privacy flaws is very different from the case of data security breaches. It is important to keep this distinction in mind to be able to develop effective responses.
The role of the browser. In the next article, I will take a broader look at identity and anonymity on the Web, and discuss the role that browsers are going to play in dictating the default level of identity in the years to come.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Ubercookies Part 2: History Stealing meets the Social Web
Recap. In the previous article I introduced ubercookies — techniques that websites can use to de-anonymize visitors. I discussed a recent paper that shows how to use history stealing along with social network group membership information to find the visitor’s identity, and I promised a stronger variant of the attack.
The observation that led me to the attack I’m going to describe is simple: social networking isn’t just about social networks — the whole web has gone social. It’s a view that you quickly internalize if you spend any time hanging out with Silicon Valley web entrepreneurs :-)
Let’s break the underlying principle of the identity-stealing attack down to its essence:
A user leaves a footprint whenever their interaction with a specific web page is recorded publicly.
De-anonymization happens when the attacker can tie these footprints together into “trails” that can then be correlated with the user’s browser history. Efficiently querying the history to identify multiple points on the trail is a challenging problem to solve, but in principle de-anonymization is possible as long as the user’s actions on different web pages happen under the same identity.
Footprints can be tied together into trails as long as all the interactions happen under the same identity. There is no need for the interactions to be on the same website.
There are two major ways in which you can interact with arbitrary websites under a unified identity, both of which are defining principles of the social web. The first is federated identity, which means you can use the same identity provider wherever you go. This is achieved through OpenID and similar mechanisms like Facebook Connect. The second is social sharing: whenever you find something interesting anywhere on the web, you feed it back to your social network.
Now let’s examine the different types of interactions in more detail.
A taxonomy of interaction on the social web.
0. The pre-social web had no social networks and no delegated identity mechanism (except for the failed attempt by Microsoft called Passport). Users created new identities on each website, authenticated via site-specific usernames and passwords to each site separately. The footprints on different sites cannot be tied together; for practical purposes there are no footprints.

1. Social networks: affiliation. In social networks, users interact with social objects and leave footprints when the actions are public. The key type of interaction that is useful for de-anonymization is the expression of affiliation: this refers to not just the group memberships studied in the recent Wondracek et al. paper, but also includes
- memberships of fan pages on Facebook
- “interests” on Livejournal
- follow relationships and plain old friend relationships on Twitter and other public social networks
- subscriptions to Youtube channels
and so on.
All of these interactions, albeit very different from the user perspective, are fundamentally the same concept:
- you “add yourself” to or affiliate yourself with some object on a social network
- this action can be publicly observed
- you almost certainly visited a URL that identifies the object before adding it.

2. The social web: sharing. When you find a page you like — any page at all — you can import it or “share” it to your social stream, on Facebook, Twitter, Google Buzz, or a social bookmarking site like Delicious. The URL of the page is almost certainly in your history, and as long as your social stream is public, your interaction was recorded publicly.

3. The social web: federated identity. When you’re reading a blog post or article on the social web, you can typically comment on it, “like” it, favorite it, rate it, etc. You do all this under your Facebook, Google or other unified identity. These actions are often public and when they are, your footprint is left on the page.
A taxonomy of attacks
The three types of social interactions above give rise to a neat taxonomy of attacks. They involve progressively easier backend processing and progressively more sophisticated history search techniques on the front end. But the execution time on the front-end doesn’t increase, so it is a net win. Here’s a table:
| Type of interaction |
Backend processing |
Type of history URL |
Location of footprint |
| Affiliation | Crawling of social network | Object in a social network | In the social network |
| Sharing | Syndication of social stream(s) from social network | Any page | In the social network |
| Federated identity | None; optional crawling | Any page | On the page |
.
1. Better use of affiliation information. The Wondracek et al. paper makes use of only group membership. One natural reason to choose groups is that there are many groups that are large, with thousands of members, so it gives us a reasonably high chance that by throwing darts in the browser history we will actually hit a few groups that the user has visited. On the other hand, if we try to use the Facebook friend list, for example, hoping to find one of the user’s friends by random chance, it probably won’t work because most users have only a few hundred friends.
But wait: many Twitter users have thousands or even millions of followers. These are known as “hubs” in network theory. Clearly, the attack will work for any kind of hubs that have predictable URLs, and users on Twitter have even more predictable URLs (twitter.com/username) than groups on various networks. The attack will also work using Youtube favorites (which show up by default on the user’s public profile or channel page) and whatever other types of affiliation we might choose to exploit, as long as there are “hubs” — nodes in the graph with high degree. Already we can see that many more websites are vulnerable than the authors envisaged.
2. Syndicating the social stream: my Delicious experiment.
The interesting thing about the social stream is that you can syndicate the stream of interactions, rather than crawling. The reasons why syndication is much easier than crawling are more practical than theoretical. First, syndicated data is intended to be machine readable, and is therefore smaller as well as easier to parse compared to scraping web pages. Second, and more importantly, you might be to get a feed of the entire site-wide activity instead of syndicating each user’s activity stream separately. Delicious allows global syndication; Twitter plans to open this “firehose” feature to all developers soon.
Another advantage of the social stream is that everything is timestamped, so you can limit yourself to recent interactions, which are more likely to be in the user’s history.
Using the delicious.com dataset made available by DAI-labor (a log of all bookmarking activity on delicious.com over several years), I did a simulated experiment using 3 months worth of data: assuming that users keep their history around for 3 months, do in fact visit every link they post on delicious, how many users would a hypothetical history stealing attack be able to identify? I had a pretty good success rate: about 60% of the users who had shared at least 2 links in the 3-month period, or about 300,000 users. This takes at most 4000-5000 Javascript history queries.
Needless to say, once Twitter opens up its firehose, Twitter users (who are far more numerous than delicious users) would also be susceptible to the same technique.
This attack is not possible to fix via server-side URL randomization. It can also be made to work using Facebook, Google Buzz, and other sharing platforms, although the backend processing required won’t be as trivial (but probably no harder than in the original attack.)
3. A somewhat random walk through the history park.
And now for an approach that potentially requires no backend data collection, although it is speculative and I can’t guess what the success rate would be. The attack proceeds in several steps:
- Identify the user’s interests by testing if they’ve visited various popular topic-specific sites. Pick one of the user’s favorite topics. Incidentally, a commenter on my previous post notes he is building exactly this capability using topic pages on Wikipedia, also with the goal of de-anonymization!
- Grab a list of the top blogs on the topic you picked from one of the blog directories. Query the history to see which of these blogs the user reads frequently. It is even possible to estimate the level of interest in a blogs by looking at the fraction of the top/recent posts from that blog that the user has visited. Pick a blog that the user seems to visit regularly.
- Look for evidence of the user leaving comments on posts. For example, on Blogger, the comment page for a post has the URL http://www.blogger.com/comment.g?blogID=<blogid>&postID=<postid>.
- Once you find a couple of posts where it looks like the user made a comment, scrape the list of people who commented on it, find the intersection. (Even a single comment might suffice; as long as you have a list of candidates, you easily verify if it’s one of them by testing user-specific URLs. More below.)
- Depending on the blogging platform, you might even be able to deduce that the user responded (or intended to respond) to a specific comment. For example, On wordpress you have the pattern http://<blogname>.wordpress.com/<postname>/?replytocom=<commentid>#respond. If you get lucky and find one of those patterns, that makes things even easier.
If at first you don’t succeed, pick a different blog and repeat.
I suspect that the most practical method would be to use a syndicated activity stream from a social network, but also to use the heuristics presented above to more efficiently search through the history.
Epilogue: Identity.
Not only has there been a movement towards a small number of identity providers on the web, there are many aggregators out there that have sprung up in order to automatically find the connections between identities across the different identity providers, and also connect online identities to physical-world databases. As Pete Warden notes:
One of the least-understood developments of the last few years is the growth of databases of personal information linked to email addresses. Rapleaf is probably the leader in this field, but even Flickr lets companies search their API for users based on an email address.
I ran my email address through his demo script and it is quite clear that virtually all of my online identities have been linked together. This is getting to be the norm; as a consequence, once an attacker gets any kind of handle on you, they can go “identity hopping” and find out a whole lot more about you.
This is also the reason that once the attacker can make a reasonable guess at the visitor’s identity, it’s easy to verify the guess. Not only can they look for user-specific URLs in your history to confirm the guess (described in detail in the Wondracek et al. paper), but all your social streams on other sites can also be combined with your history to corroborate your identity.
Up next in the Ubercookies series: So that’s pretty bad. But it’s going to get worse before it can get better :-) In the next article, I will describe an entirely different attack strategy to get at your identity by exploiting a bug in a specific identity provider’s platform.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Cookies, Supercookies and Ubercookies: Stealing the Identity of Web Visitors
 Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Cookies. Most people are aware that their web browsing activity over time and across sites can be tracked using cookies. When you are being tracked, it can be deduced that the same person visited certain sites at certain times, but the sites doing the tracking don’t know who you are, i.e., you name, etc., unless you choose to tell them in some way, such as by logging in.
Cookies are easy to delete, and so there’s been a big impetus in the Internet advertising industry to discover and deploy more robust tracking mechanisms.
Supercookies. You may surprised to find just how helpless a user is against a site (or more usually, a network of sites) that is truly determined to track them. There are Flash cookies, much harder to delete, some of which respawn the regular HTTP cookies that you delete. The EFF’s Panopticlick project demonstrates many “browser fingerprinting” methods which are more sophisticated. (Jonathan Mayer’s senior thesis contained a smaller-scale demonstration of some of those techniques).
A major underlying reason for a lot of these problems is that any browser feature that allows a website to store “state” on the client can be abused for tracking, and there are a bewildering variety of these. There is a great analysis in a paper by my Stanford colleagues. One of the points they make is that co-operative tracking by websites is essentially impossible to defend against.
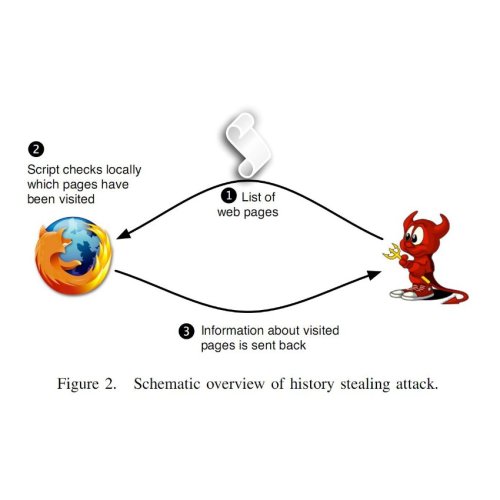
Ubercookies: history stealing. Now let’s get to the scary stuff: uncovering identity. History stealing or history sniffing is an unintended consequence of the way the web is designed; it allows a website to learn which URLs you’ve been to. While a site can’t simply ask your browser for a list of visited URLs, it can ask “yes/no” questions and your browser will faithfully respond. The most common way of doing this is by injecting invisible links into the page using Javascript and exploiting the fact that the CSS link color attribute depends on whether the link has been visited or not.
History stealing has been known for a decade, and browser vendors have failed to fix it because it cannot be fixed without sacrificing some useful functionality (the crude way is to turn off visited link coloring altogether; a subtler solution is SafeHistory). Increasingly worse consequences have been discovered over the years: for example, a malicious site can learn which bank you use and customize a phishing page accordingly. But a paper (full text, PDF) coming out at this year’s IEEE S&P conference at Oakland takes it to a new level.
Identity. Let’s pause for a second and think about what finding your identity means. In the modern, social web, social network accounts have become our de-facto online identities, and most people reveal their name and at least some other real-world information about ourselves on our profiles. So if the attacker can discover the URL of your social network profile, we can agree that he has identified you for all practical purposes. And the new paper shows how to do just that.
The attack relies on the following observations:
- Almost all social networking sites have some kind of “group” functionality: users can add themselves to groups.
- Users typically add themselves to multiple groups, at least some of which are public.
- Group affiliations, just like your movie-watching history and many other types of attributes, are sufficient to fingerprint a user. There’s a high chance there’s no one else who belongs to the same set of groups that you do (or is even close). [Aside: I used this fact to show that Lending Club data can be de-anonymized.]
- Users who belong to a group are likely to visit group-specific URLs that are predictable.
Put the above facts together, and the attack emerges: the attacker (an arbitrary website you visit, without the co-operation of whichever social network is used as an attack enabler) uses history stealing to test a bunch of group-related URLs one by one until he finds a few (public) groups that the anonymous user probably belongs to. The attacker has already crawled the social network, and therefore knows which user belongs to which groups. Now he puts two and two together: using the list of groups he got from the browser, he does a search on the backend to find the (usually unique) user who belongs to all those groups.
Needless to say, this is a somewhat simplified description. The algorithm can be easily modified so that it will work even if some of the groups have disappeared from your history (say because you clear it once in a while) or if you’ve visited groups you’re not a member of. The authors demonstrated that the attack with real users on the Xing network, and also showed theoretically that it is feasible on a number of other social networks including Facebook and Myspace. It takes a few thousand Javascript queries and runs in a few seconds on modern browsers, which makes it pretty much surreptitious.
Fallout. There are only two ways to try to fix this. The first is for all the social networking sites to change their URL patterns by randomizing them so that point 4 above (predictable URL identifying that you belong to a group) is no longer true. The second is for all the browser vendors to fix their browsers so that history stealing is no longer possible.
The authors contacted several of the social networks; Xing quickly implemented the URL randomization fix, which I find surprising and impressive. Ultimately, however, Xing’s move will probably be no more than a nice gesture, for the following reason.
Over the last few days, I have been working on a stronger version of this attack which:
- can make use of every URL in the browser history to try and identify the user. This means that server-side fixes are not possible, because literally every site on the web would need to implement randomization.
- avoids the costly crawling step, further lowering the bar to executing the attack.
That leaves browser-based fixes for history stealing, which hasn’t happened in the 10 years that the problem has been known. Will browsers vendors finally accept the functionality hit and deal with the problem? We can hope so, but it remains to be seen.
In the next article, I will describe the stronger attack and also explain in more detail why your profile page on almost any website is a very strong identifier.
Thanks to Adam Bossy for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.


{kind=link}