The Fallacy of Anonymous Institutions
December 15, 2008 at 10:48 am 3 comments
The graph below is from the paper “Chains of affection: The structure of adolescent romantic and sexual networks.” The name of the school that the data was collected from is not revealed, and is given the working name “Jefferson High.” It is part of the National Longitudinal Study of Adolescent Health, containing very detailed health information on 100,000 high school students in 140 schools. In 12 of the schools, the entire sexual network was mapped out.
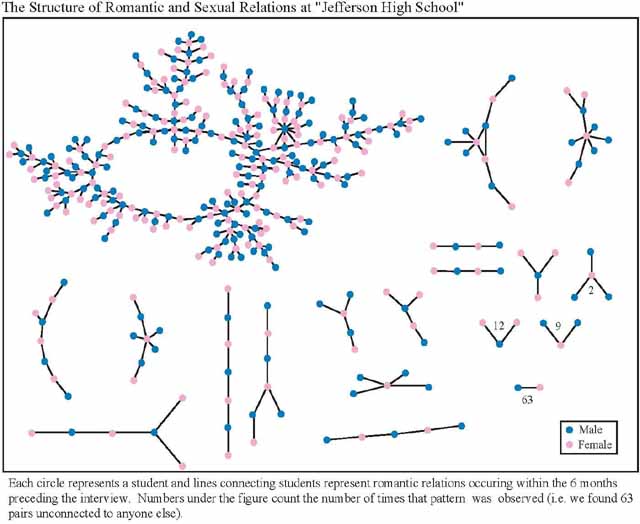
Clearly, the authors felt that concealing the identity of the school is important for protecting the privacy of the participants. It’s not hard to see why: firstly, the aggregate information presented in the study could by itself be unpleasant, especially facts about the prevalence of adolescent sexual activity in a conservative rural town (see below). Second, and more importantly, knowing the identity of the school can lead to further de-anonymization of the individuals in the network.
The graph above is rich enough that a few individuals can identify themselves purely based on the local information available to them, and thus learn things about their neighbors in the graph. A group of individuals getting together will have an even easier time of it. Furthermore, the actual paper provides a richer, temporally ordered version of the graph above.
But even strangers may benefit: depending on how well the temporal information in the sexual graph correlates with other temporal information that may be available, say from Facebook, de-anonymization might be possible with little or no co-operation from the subjects themselves. Soon, I will have more to say about research results on de-anonymizing graphs with loosely correlated external/auxiliary data.
Having established the privacy risk, let’s see how easy it is to re-identify Jefferson High. The authors give us these helpful clues:
“Jefferson High School” is an almost all-white high school of roughly 1000 students located in a mid-sized mid-western town. Jefferson High is the only public high school in the town. The town, “Jefferson City” is over an hour away by car from the nearest large city. Jefferson City is surrounded by beautiful countryside, home to many agricultural enterprises. The town itself is working class, although there remain some vestiges of better times. At one period, the town served as a resort for city dwellers, drawing an annual influx of summer visitors. This is no longer the case, and many of the old resort properties show signs of decay. The community is densely settled. At the time of our fieldwork, students were reacting to the deaths of two girls killed in an automobile accident.
Some further facts presented have high amusement value, and are equally useful for re-identification:
Jefferson students earn lower grades, are suspended more, feel less attached to school, and come from poorer families than those at comparable schools. They are more likely than students in other high schools to have trouble paying attention, have lower self-esteem, pray more, have fewer expectations about college, and are more likely to have a permanent tattoo. Compared to other students in large disproportionately white schools, adolescents in Jefferson High are more likely to drink until they are drunk. In schools of comparable race and size, on average 30% of 10th-12th grade students smoke cigarettes regularly, whereas in Jefferson, 36% of all 10th to 12th graders smoke. Drug use is moderate, comparable to national norms. Somewhat more than half of all students report having had sex, a rate comparable to the national average, and only slightly higher than observed for schools similar with respect to race and size. Nevertheless, if Jefferson is not Middletown, it looks like an awful lot like it. The adolescents at Jefferson High are pretty normal. In describing the events of the past year, many students report that there is absolutely nothing to do in Jefferson. For fun, students like to drive to the outskirts of town and get drunk. Jefferson is a close-knit insular predominantly working-class community which offers few activities for its youth.
A database of public schools in the U.S. is available for sale for $75, containing very detailed information about each school. I’m quite confident that the information in there is sufficient to re-identify Jefferson High.
This thesis of this blog that the amount of entropy required to de-anonymize an individual — 33 bits — is low enough that it doesn’t offer meaningful protection in most circumstances. Obviously, the argument applies even more strongly to the anonymity of a well-defined group of people.
Let’s be clear: the paper is from 1994; who slept with whom in high school is not a huge deal a decade and a half later. However, the problem is systemic, and IRBs (Institutional Review Boards) keep blithely approving releases of data with such nominal de-identification applied. The re-identification of the institutional affiliation of an entire population of a study is of more concern from the privacy perspective than the de-anonymization of individual identities: it needs to be done only once, and affects hundreds or thousands of individuals.
Recently, a group of researchers from the Berkman Center released a dataset of Facebook profile information from an entire cohort (the class of 2009) of college students from “an anonymous, northeastern American university.” It was promptly de-anonymized by Michael Zimmer, who revealed that it was Harvard College:
As I noted here, the press release and the public codebook for the dataset provided many clues to where the data came from: we know it is a northeastern US university, it is private, co-ed, and whose class of 2009 initially had 1640 students in it. A quick search for schools reveals there are only 7 private, co-ed colleges in New England states (CT, ME, MA, NH, R , VT) with total undergraduate populations between 5000 and 7500 students (a likely range if there were 1640 in the 2006 freshman class): Tufts University, Suffolk University, Yale University, University of Hartford, Quinnipiac University, Brown University, and Harvard College.
[…]
Finally, and perhaps most convincingly, only Harvard College offers the specific variety of the subjects’ majors that are listed in the codebook. While nearly all univerersities offer the common majors of “History”, “Chemistry” or “Economics”, one only needs to search for the more uniquely phrased majors to discover a shared home institution.
Another amusing example is a paper on mobile phone call graphs which attempts to keep the identity of an entire country secret. I found that the approximate population of the country reported in the paper together with the mobile phone penetration rate is sufficient to uniquely identify it.
Suppressing the identity of your study population has some privacy benefits: at least, it won’t show up in google searches. But relying on it for any kind of serious privacy protection would be foolish. Scrubbing an entire dataset or research paper of clues about the study population can be hard or impossible; further, a single study participant corroborating the published results or methodology might be sufficient for de-anonymization of the group. The only solution is therefore to assume that the identity of the study population will be discovered, and to try to ensure that individual identities will still be safe from re-identification.
Entry filed under: Uncategorized. Tags: anonymity, blog_dape, privacy, re-identification, social networks.
3 Comments Add your own
Leave a comment
Trackback this post | Subscribe to the comments via RSS Feed


1. Zachary Schrag | December 16, 2008 at 2:24 am
Zachary Schrag | December 16, 2008 at 2:24 am
Some historical perspective, from a manuscript first written in 1954:
“It is a popular pastime of academic cognoscenti to disclose ‘anonymous’ towns and authors. . . . Without undertaking any special search, we have noticed the real names of ‘Middletown,’ ‘Southerntown,’ ‘Cotton,’ ‘Yankee City,’ ‘Cantonville,’ ‘Elmtown,’ and ‘San Carlos’ identified in print: it is standard form for book reviewers to reveal the name of an ‘anonymous’ community.”
Harold Orlans, “Ethical Problems and Values in Anthropological Research,” in U.S. Congress, House Committee on Government Operations, Research and Technical Programs Subcommittee, The Use of Social Research in Federal Domestic Programs: Part IV—Current Issues in the Administration of Federal Social Research (90th Cong., 1st. sess., 1967), 362.
2. dfb | March 8, 2009 at 8:51 am
dfb | March 8, 2009 at 8:51 am
This is very interesting. Even if you found several high schools that matched the description, it would still be much easier to de-anonymize than considering the several thousand schools in the midwest.
3. IRB is incompatible with open access to data « Ben Mazzotta’s Weblog | March 12, 2009 at 9:30 pm
[…] a comment » Mathematician Arvind Narayanan at his blog 33 Bits writes a compelling post on the failure of efforts to protect the identities of individuals in public domain, scientific […]