Posts tagged ‘tracking’
Online price discrimination: Conspicuous by its absence
The mystery about online price discrimination is why so little of it seems to be happening.
Consumer advocates and journalists among others have been trying to find smoking gun evidence of price discrimination — the overt kind where different customers are charged different prices for identical products based on how much they are willing to pay. (By contrast, examples of covert or concealed price discrimination abound; see, for example, my 2011 article.) Back in 2000 Amazon tried a short-lived experiment where prices of DVDs for new and for regular users were different. But that remains essentially the only example.
This should be surprising. Tailoring prices to individuals is far more technically feasible online than offline, since shoppers are either identified or at least have loads of behavioral data associated with their pseudonymous cookies. The online advertising industry claims that this is highly effective for targeting ads; estimating consumers’ willingness to pay shouldn’t be much harder. Clearly, price discrimination has benefits to firms engaging in it by allowing them to capture more of the “consumer surplus.” (Whether or not it is beneficial to consumers is a more controversial question that I will defer to a future post.) In fact, based on technical feasibility and economic benefits, one might expect the practice to be pervasive.
The evidence (or lack thereof)
A study out of Spain last year took a comprehensive look at online merchants, by far the most thorough analysis of its kind. They created two “personas” with different browsing histories — one of which visited discount sites and the other visited sites for luxury products. Each persona then browsed 200 e-commerce sites as well as search engines to see if they were treated differently. Here’s what the authors found:
- There is evidence for search discrimination or steering where the high- and low-income personas are shown ads for high-end and low-end products respectively. In my opinion, the line between this practice and plain old behavioral advertising is very, very slim. [1]
- There is no evidence for price discrimination based on personas/browsing histories.
- Three of the 200 retailers including Staples varied prices based on the user’s location, but necessarily not in a way that can’t be explained by costs of doing business.
- Visitors coming from one particular deals site (nextag.com) saw lower prices at various retailers. (Discounting and “deals” are very common forms of concealed price discrimination.)
A new investigation by the Wall Street Journal analyzes Staples in more detail. While the Spain study found geographic variation in prices, the WSJ study goes further and shows a strong correlation between lower prices and consumers’ ability to drive to competitors’ stores, which is an indicator of willingness to pay. I’m not 100% convinced that they’ve ruled out alternative hypotheses, but it does seem plausible that Staples’ behavior constitutes actual price discrimination, even though geography is a far cry from utilizing behavioral data about individuals.
Other findings in the WSJ piece are websites that offer discounts for mobile users and location-dependent pricing on Lowe’s and Home Depot’s websites but with little evidence of being based on anything but costs of doing business.
So there we have it. Both studies are very thorough, and I commend the authors, but I consider their results to be mostly negative — very few companies are varying prices at all and none are utilizing anywhere near the full extent of data available about users. Other price discrimination controversies include steering by Orbitz and a hastily-retracted announcement by Coca Cola for vending machines that would tailor prices to demand. Neither company charged or planned to charge different prices for the same product based on who the consumer was.
In short, despite all the hubbub, I find overt price discrimination conspicuous by its absence. In a follow-up post I will propose an explanation for the mystery and see what we can learn from it.
[1] This is an automatic consequence of collaborative recommendation that suggests products to users based on what similar users have clicked on/purchased in the past. It does not require that any explicit inference of the consumer’s level of affluence be made by the system. In other words, steering, bubbling etc. are inherent features of collaborative filtering algorithms which drive personalization, recommendation and information retrieval on the Internet. This fact greatly complicates attempts to define, detect or regulate unfair discrimination online.
Thanks to Aleecia McDonald for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
New Developments in Deanonymization
This post is a roundup of developments in deanonymization in the last few months. Let’s start with two stories relating to how a malicious website can silently discover the identity of a visitor, which is an insidious type of privacy breach that I’ve written about quite a bit (1, 2, 3, 4, 5, 6).
Firefox bug exposed your identity. The first is a vulnerability resulting from a Firefox bug in the implementation of functions like exec and test. The bug allows a website to learn the URL of an embedded iframe from some other domain. How can this lead to uncovering the visitor’s identity? Because twitter.com/lists redirects to twitter.com/<username>/lists. This allows a malicious website to open a hidden iframe pointing to twitter.com/lists, query the URL after redirection, and learn the visitor’s Twitter handle (if they are logged in). [1,2]
This is very similar to a previous bug in Firefox that led to the same type of vulnerability. The URL redirect that was exploited there was google.com/profiles/me → user-specific URL. It would be interesting to find and document all such generic-URL → user-specific-URL redirects in major websites. I have a feeling this won’t be the last time such redirection will be exploited.
Visitor deanonymization in the wild. The second story is an example of visitor deanonymization happening in the wild. It appears that the technique utilizes a tracking cookie from a third-party domain to which the visitor previously gave their email and other info., in other words, #3 in my five-fold categorization of ways in which identity can be attached to browsing logs.
I don’t consider this instance to be particularly significant — I’m sure there are other implementations in the wild — and it’s not technically novel, but this is the first time as far as I know that it’s gotten significant attention from the public, even if only in tech circles. I see this as a first step in a feedback loop of changing expectations about online anonymity emboldening more sites to deanonymize visitors, thus further lowering the expectation of privacy.
Deanonymization of mobility traces. Let’s move on to the more traditional scenario of deanonymization of a dataset by combining it with an auxiliary, public dataset which has users’ identities. Srivatsa and Hicks have a new paper with demonstrations of deanonymization of mobility traces, i.e., logs of users’ locations over time. They use public social networks as auxiliary information, based on the insight that pairs of people who are friends are more likely to meet with each other physically. The deanonymization of Bluetooth contact traces of attendees of a conference based on their DBLP co-authorship graph is cute.
This paper adds to the growing body of evidence that anonymization of location traces can be reversed, even if the data is obfuscated by introducing errors (noise).
So many datasets, so little time. Speaking of mobility traces, Jason Baldridge points me to a dataset containing mobility traces (among other things) of 5 million “anonymous” users in the Ivory Coast recently released by telecom operator Orange. A 250-word research proposal is required to get access to the data, which is much better from a privacy perspective than a 1-click download. It introduces some accountability without making it too onerous to get the data.
In general, the incentive for computer science researchers to perform practical demonstrations of deanonymization has diminished drastically. Our goal has always been to showcase new techniques and improve our understanding of what’s possible, and not to name and shame. Even if the Orange dataset were more easily downloadable, I would think that the incentive for deanonymization researchers would be low, now that the Srivatsa and Hicks paper exists and we know for sure that mobility traces can be deanonymized, even though the experiments in the paper are on a far smaller scale.
Head in the sand: rational?! I gave a talk at a privacy workshop recently taking a look back at how companies have reacted to deanonymization research. My main point was that there’s a split between the take-your-data-and-go-home approach (not releasing data because of privacy concerns) and the head-in-the-sand approach (pretending the problem doesn’t exist). Unfortunately but perhaps unsurprisingly, there has been very little willingness to take a middle ground, engaging with data privacy researchers and trying to adopt technically sophisticated solutions.
Interestingly, head-in-the-sand might be rational from companies’ point of view. On the one hand, researchers don’t have the incentive for deanonymization anymore. On the other hand, if malicious entities do it, naturally they won’t talk about it in public, so there will be no PR fallout. Regulators have not been very aggressive in investigating anonymized data releases in the absence of a public outcry, so that may be a negligible risk.
Some have questioned whether deanonymization in the wild is actually happening. I think it’s a bit silly to assume that it isn’t, given the economic incentives. Of course, I can’t prove this and probably never can. No company doing it will publicly talk about it, and the privacy harms are so indirect that tying them to a specific data release is next to impossible. I can only offer anecdotes to explain my position: I have been approached multiple times by organizations who wanted me to deanonymize a database they’d acquired, and I’ve had friends in different industries mention casually that what they do on a daily basis to combine different databases together is essentially deanonymization.
[1] For a discussion of why a social network profile is essentially equivalent to an identity, see here and the epilog here.
[2] Mozilla pulled Firefox 16 as a result and quickly fixed the bug.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
Tracking Not Required: Behavioral Targeting
Co-authored by Jonathan Mayer and Subodh Iyengar.
In the first installment of the Tracking Not Required series, we discussed a relatively straightforward case: frequency capping. Now let’s get to the 800-pound gorilla, behaviorally targeted advertising, putatively the main driver of online tracking. We will show how to swap a little functionality for a lot of privacy.
Admittedly, implementing behavioral targeting on the client is hard and will require some technical wizardry. It doesn’t come for “free” in that it requires a trade-off in terms of various privacy and deployability desiderata. Fortunately, this has been a fertile topic of research over the past several years, and there are papers describing solutions at a variety of points on the privacy-deployability spectrum. This post will survey these papers, and propose a simplification of the Adnostic approach — along with prototype code — that offers significant privacy and is straightforward to implement.
Goals. Carrying out behavioral advertising without tracking requires several things. First, the user needs to be profiled and categorized based on their browsing history. In nearly all proposed solutions, this happens in the user’s browser. Second, we need an algorithm for selecting targeted ads to display each time the user visits a page. If the profile is stored locally and not shared with the advertising company, this is quite nontrivial. The final component is for reporting of ad impressions and clicks. This component must also deal with click fraud, impression fraud and other threats.
Existing approaches
The chart presents an overview of existing and proposed architectures.
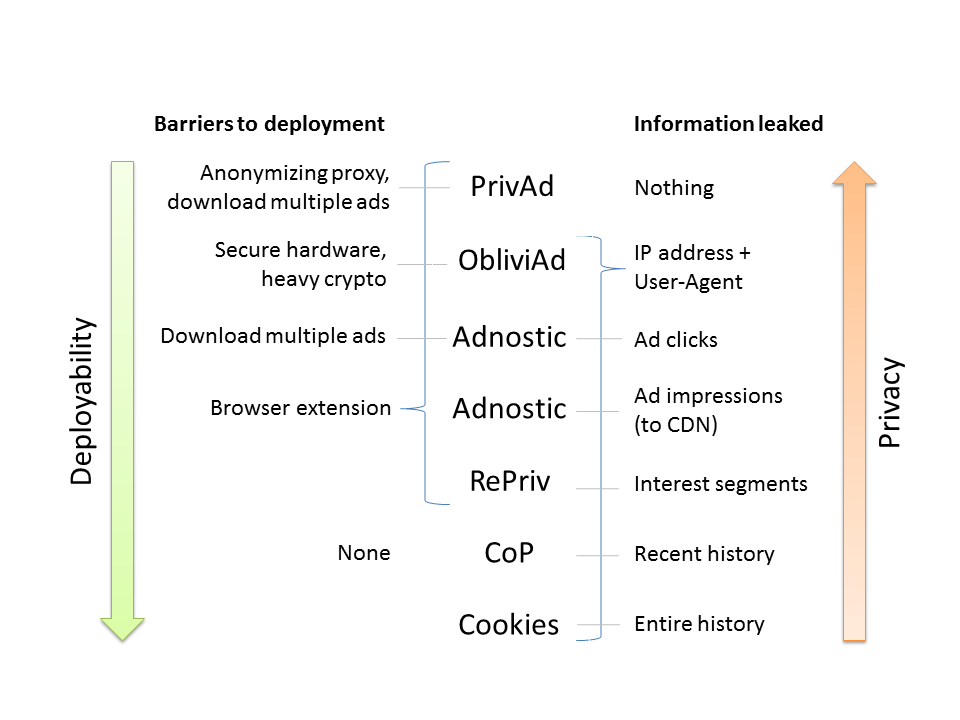
“Cookies” refers to the status quo of server-side tracking; all other architectures are presented in research papers summarized in the Do Not Track bibliography page. CoP stands for “Client-only Profiles,” the architecture proposed by Bilenko and Richardson.
Several points of note. First, everything except PrivAd — which uses an anonymizing proxy — reveals the IP address, and typically the User Agent and Referer to the ad company as part of normal HTTP requests. Second, everything except CoP (and the status quo of tracking cookies) requires software installation. Opinions vary on just how much of a barrier this is. Third, we don’t take a stance on whether PrivAd is more deployable than ObliviAd or vice-versa; they both face significant hurdles. Finally, Adnostic can be used in one of two modes, hence it is listed twice.
There is an interesting technological approach, not listed above, that works by exposing more limited referer information. Without the referer header (or an equivalent), the ad server may identify the user but will not learn the first-party URL, and thus will not be able to track. This will be explored in more depth in a future article.
New approach. In the solution we propose here, the server is recruited for profiling, but doesn’t store the profile. This avoids the need for software installation and allows easy deployability. In addition, non-tracking is externally verifiable, to the extent that IP address + User-Agent is not nearly as effective for tracking as cookie-based unique identifiers.[1] Like CoP, and unlike Adnostic, each ad company can only profile users during visits to pages that it has a third-party presence on, rather than all pages.
Profiling algorithm.
1. The user visits a page that has embedded content from the ad company.
2. JavaScript in the ad company’s content sends the top-level URL to a special classifier service run by the ad company. (The classifier is run on a separate domain. It does not have any cookies or other information specific to the user.)
3. The classifier returns a topic classification of the page.
4. The ad company’s JavaScript receives the page classification and uses it to update the user’s behavioral profile in HTML5 storage. The JavaScript may also consider other factors, such as how long the user stayed on the page.
There is a fair degree of flexibility in steps 3 and 4 — essentially any profiling algorithm can be implemented by appropriately splitting it into a server-side component that classifies individual web pages and a client-side component that analyzes the user’s interaction with these pages.
Ad serving and accounting.
The ad serving process in our proposal is the same as in Adnostic — the server sends a list of ads along with metadata describing each ad, and the client-side component picks the ad that best matches the locally stored profile. To avoid revealing which ad was displayed, the client can either download all (say, 10) ads in the list while displaying only one, or the client downloads only one ad, but ads are served from a different domain which does not share cookies with the tracking domain. Note the similarity to our frequency capping approach, both in terms of the algorithm and its privacy properties.
Accounting, i.e., billing the right advertiser is also identical to Adnostic for the cost-per-click and cost-per-impression models; we refer the reader there. Discussing the cost-per-action model is deferred to a future post.
Implementation. We implemented our behavioral targeting algorithm using HTML 5 local storage. As with our frequency capping implementation, we found performance was exceptionally fast in modern desktop and mobile browsers. For simplicity, our implementation uses a static local database mapping websites to interest segments and a binary threshold for determining interests. In practice, we expect implementers would maintain the mapping server-side and apply more sophisticated logic client-side.
We also present a different work-in-progress implementation that’s broader in scope, encompassing retargeting, behavioral targeting and frequency capping.
Conclusion. Certainly there are costs to our approach — a “thick-client” model will always be slightly more inconvenient to deploy and maintain than a server-based model, and will probably have a lower targeting accuracy. However, we view these costs as minimal compared to the benefits. Some compromise is necessary to get past the current stalemate in web tracking.
Technological feasibility is necessary, but not sufficient, to change the status quo in online tracking. The other key component is incentives. That is why Do Not Track, standards and advocacy are crucial to the online privacy equation.
[1] The engineering and business reasons for this difference in effectiveness will be discussed in a future post.
To stay on top of future posts, subscribe to the RSS feed or follow me on Google+.
Web Privacy Measurement: Genesis of a Community
Last week I participated in the Web Privacy Measurement conference at Berkeley. It was a unique event because the community is quite new and this was our very first gathering. The WSJ Data Transparency hackathon is closely related; the Berkeley conference can be thought of as an academic counterpart. So it was doubly fascinating for me — both for the content and because of my interest in the sociology of research communities.
A year ago I explained that there is an information asymmetry when it comes to online privacy, leading to a “market for lemons.” The asymmetry exists for two main reasons: one is that companies don’t disclose what data they collect about you and what they do with it; the second is that even if they do, end users don’t have the capacity to aggregate and process that information and make decisions on the basis of it.
The Web Privacy Measurement community essentially exists to mitigate this asymmetry. The primary goal is to ferret out what is happening to your data online, and a secondary one is making this information useful by pushing for change, building tools for opt-out and control, comparison of different players, etc. The size of the community is an indication of how big the problem has gotten.
Before anyone starts trotting out the old line, “see, the market can solve everything!”, let me point out that the event schedule demonstrates, if anything, the opposite. The majority of what is produced here is intended wholly or partly for the consumption of regulators. Like many others, I found the “What privacy measurement is useful for policymakers?” panel to be the most interesting one. And let’s not forget that most of this is Government-funded research to begin with.
This community is very different from the others that I’ve belonged to. The mix of backgrounds is extraordinary: researchers mainly from computing and law, and a small number from other disciplines. Most of the researchers are academics, but a few work for industrial research labs, a couple are independent, and one or two work in Government. There were also people from companies that make privacy-focused products/services, lawyers, hobbyists, scholars in the humanities, and ad-industry representatives. Overall, the community has a moderately adversarial relationship with industry, naturally, and a positive relationship with the press, regulators and privacy advocates.
The make-up is somewhat similar to the (looser-knit) group of researchers and developers building decentralized architectures for personal data, a direction that my coauthors and I have taken a skeptical view of in this recent paper. In both cases, the raison d’être of the community is to correct the imbalance of power between corporations and the public. There is even some overlap between the two groups of people.
The big difference is that the decentralization community, typified by Diaspora, mostly tries to mount a direct challenge and overthrow the existing order, whereas our community is content to poke, measure, and expose, and hand over our findings to regulators and other interested parties. So our potential upside is lower — we’re not trying to put a stop to online tracking, for example — but the chance that we’ll succeed in our goals is much higher.
Exciting times. I’m curious to see how things evolve. But this week I’m headed to PLSC, which remains my favorite privacy-related conference.
Thanks to Aleecia McDonald for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Google+.
Printer Dots, Pervasive Tracking and the Transparent Society
So far in the fingerprinting series, we’ve seen how a variety of objects and physical devices [1, 2, 3, 4], often even supposedly identical ones, can be uniquely fingerprinted. This article is non-technical; it is an opinion on some philosophical questions about tracking and surveillance.
Here’s a fascinating example of tracking that’s all around you but that you’re probably unaware of:
My source for this is the EFF’s Seth Schoen, who has made his presentation on the subject available.
![]()
The dots are not normally visible, but can be seen by a variety of methods such as shining a blue LED flashlight, magnification under a microscope or scanning the document with a commodity scanner. The pattern of dots typically encodes the device serial number and a timestamp; some parts of the code are yet unidentified. There are interesting differences between the codes used by different manufacturers. [1] Some examples are shown in the pictures. There’s a lot more information in the presentation.

Pattern of dots from three different printers: Epson, HP LaserJet and Canon.
Schoen says the dots could have been the result of the Secret Service pressuring printer manufacturers to cooperate, going back as far as the 1980s. The EFF’s Freedom of Information Act request on the matter from 2005 has been “mired in bureaucracy.”
The EFF as well as the Seeing Yellow project would like to see these dots gone. The EFF has consistently argued against pervasive tracking. In this article on biometric surveillance, they say:
EFF believes that perfect tracking is inimical to a free society. A society in which everyone’s actions are tracked is not, in principle, free. It may be a livable society, but would not be our society.
Eloquently stated. You don’t have to be a privacy advocate to see that there are problems with mass surveillance, especially by the State. But I’d like to ask the question: can we really hope to stave off a surveillance society forever, or are efforts like the Seeing Yellow project just buying time?
My opinion is that it impossible to put the genie back into the bottle — the cost of tracking every person, object and activity will continue to drop exponentially. I hope the present series of articles has convinced you that even if privacy advocates are successful in preventing the deployment of explicit tracking mechanisms, just about everything around you is inherently trackable. [2]
And even if we can prevent the State from setting up a surveillance infrastructure, there are undeniable commercial benefits in tracking everything that’s trackable, which means that private actors will deploy this infrastructure, as they’ve done with online tracking. If history is any indication, most people will happily allow themselves to be tracked in exchange for free or discounted services. From there it’s a simple step for the government to obtain the records of any person of interest.
If we accept that we cannot stop the invention and use of tracking technologies, what are our choices? Our best hope, I believe, is a world in which the ability to conduct tracking and surveillance is symmetrically distributed, a society in which ordinary citizens can and do turn the spotlight on those in power, keeping that power in check. On the other hand, a world in which only the government, large corporations and the rich are able to utilize these technologies, but themselves hide under a veil of secrecy, would be a true dystopia.
Another important principle is for those who do conduct tracking to be required to be transparent about it, to have social and legal processes in place to determine what uses are acceptable, and to allow opting out in contexts where that makes sense. Because ultimately what matters in terms of societal freedom is not surveillance itself, but how surveillance affects the balance of power. To be sure, the society I describe — pervasive but transparent tracking, accessible to everyone, and with limited opt-outs — would be different from ours, and would take some adjusting to, but that doesn’t make it worse than ours.
I am hardly the first to make this argument. A similar position was first prominently articulated by David Brin his 1999 book Transparent Society. What the last decade has shown is just how inevitable pervasive tracking is. For example, Brin focused too much on cameras and assumed that tracking people indoors would always be infeasible. That view seems almost quaint today.
Let me be clear: I have absolutely no beef with efforts to oppose pervasive tracking. Even if being watched all of the time is our eventual destiny, society won’t be ready for it any time soon — these changes take decades if not generations. The pace at which the industry wants us to make us switch to “living in public” is far faster than we’re capable of. Buying time is therefore extremely valuable.
That said, embracing the Transparent Society view has important consequences for civil libertarians. It suggests working toward an achievable if sub-optimal goal instead of an ideal but impossible one. It also suggests that the “democratization of surveillance” should be encouraged rather than feared.
Here are some currently hot privacy and civil-liberties issues that I think will have a significant impact on the distribution of power in a ubiquitous-surveillance society: the right to videotape on-duty police officers and other public officials, transparent government initiatives including FOIA requests, and closer to my own interests, the Do Not Track opt-out mechanism, and tools like FourthParty which have helped illuminate the dark world of online tracking.
Let me close by calling out one battle in particular. Throughout this series, we’ve seen that fingerprinting techniques have security-enhancing applications (such as forensics), as well as privacy-infringing ones, but that most research papers on fingerprinting consider only the former question. I believe the primary reason is that funding is for the most part available only for the former type of research and not for the latter. However, we need a culture of research into privacy-infringing technologies, whether funded by federal grants or otherwise, in order to achieve the goals of symmetry and transparency in tracking.
[1] Note that this is just an encoding and not encryption. The current system allows anyone to read the dots; public-key encryption would allow at least nominally restricting the decoding ability to only law-enforcement personnel, but there is no evidence that this is being done.
[2] This is analogous to the cookies-vs-fingerprinting issue in online tracking, and why cookie-blocking alone is not sufficient to escape tracking.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
Fingerprinting of RFID Tags and High-Tech Stalking
Previous articles in this series looked at fingerprinting of blank paper and digital cameras. This article is about fingerprinting of RFID, a domain where research has directly investigated the privacy threat, namely tracking people in public.
The principle behind RFID fingerprinting is the same as with digital cameras:
The basics. First let’s get the obvious question out of the way: why are we talking about devious methods of identifying RFID chips, when the primary raison d’être of RFID is to enable unique identification? Why not just use them in the normal way?
The answer is that fingerprinting, which exploits the physical properties of RFID chips rather than their logical behavior, allows identifying them in unintended ways and in unintended contexts, and this is powerful. RFID applications, for example in e-passports or smart cards, can often be cloned at the logical level, either because there is no authentication or because authentication is broken. Fingerprinting can make the system (more) secure, since fingerprints arise from microscopic randomness and there is no known way to create a tag with a given fingerprint.
If sensor patterns in digital cameras are a relatively clean example of fingerprinting, RF (and anything to do with the electromagnetic spectrum in general) is the opposite. First, the data is an arbitrary waveform instead of an fixed-size sequence of bits. This means that a simple point-by-point comparison won’t work for fingerprint verification; the task is conceptually more similar to algorithmically comparing two faces. Second, the probe signal itself is variable. RFID chips are passive: they respond to the signal produced by the reader (and draw power from it).[1] This means that the fingerprinting system is in full control of what kind of signal to interrogate the chip with. It’s a bit like being given a blank canvas to paint on.
Techniques. A group at ETH Zurich has done some impressive work in this area. In their 2009 paper, they report being able to compare an RFID card with a stored fingerprint and determine if they are the same, with an error rate of 2.5%–4.5% depending on settings.[2] They use two types of signals to probe the chip with — “burst” and “sweep” — and extract features from the response based on the spectrum.

Chip response to different signals. Fingerprints are extracted from characteristic features of these responses.
Other papers have demonstrated different ways to generate signals/extract features. A University of Arkansas team exploited the minimum power required to get a response from the tag at various frequencies. The authors achieved a 94% true-positive rate using 50 identical tags, with only a 0.1% false-positive rate. (About 6% of the time, the algorithm didn’t produce an output.)
Yet other techniques, namely the energy and Q factor of higher harmonics were studied in a couple of papers out of NIST. In the latter work, they experimented with 20 cards which consisted of 4 batches of 5 ‘identical’ cards in each. The overall identification accuracy was 96%.
It seems safe to say that RFID fingerprinting techniques are still in their infancy, and there is much room for improvement by considering new categories of features, by combining different types of features, or by using different classification algorithms on the extracted features.
Privacy. RF fingerprinting, like other types of fingerprinting, shows a duality between security-enhancing and privacy-infringing applications, but in a less direct way. There are two types of RFID systems: “near-field” based on inductive coupling, used in contactless smartcards and the like, and “far field” based on backscatter, used in vehicle identification, inventory control, etc. The papers discussed so far pertain to near-field systems. There are no real privacy-infringing applications of near-field RF fingerprinting, because you can’t get close enough to extract a fingerprint without the owner of the tag knowing about it. Far-field systems, to which we will now turn, are ideally suited to high-tech stalking.
In a recent paper, the Zurich team mentioned earlier investigated the possibility of tracking a people in a shopping mall based on strategically placed sensors, assuming that shoppers have several (far-field) RFID tags on them. The point is that it is possible to design chips that prevent tracking at the logical level by authenticating the reader, but this is impossible at the physical level.
Why would people have RFID tags on them? Tags used for inventory control in stores, and not deactivated at the point-of-sale are one increasingly common possibility — they would end up in shopping bags (or even on clothes being worn, although that’s less likely). RFID tags in wallets and medical devices are another source; these are tags that the user wants to be present and functional.
What makes the tracking device the authors built powerful is that it is low-cost and can be operated surreptitiously at some distance from the victim: up to 2.75 meters, or 9 feet. They show that 5.4 bits of entropy can be extracted from a single tag, which means that 5 tags on a person gives 22 bits, easily enough to distinguish everyone who might be in a particular mall.
To assess the practical privacy risk, technological feasibility is only one dimension. We also need to ask who the adversary is and what the incentives are. Tracking people, especially shoppers, in physical space has the strongest incentive of all: selling products. While online tracking is pervasive, the majority of shopping dollars are still spent offline, and there’s still no good way to automatically identify people when they are in the vicinity in order to target offers to them. Facial recognition technology is highly error-prone and creeps people out, and that’s where RF fingerprinting comes in.
That said, RF fingerprinting is only one of the many ways of passively tracking people en masse in physical space — unintentional leaks of identifiers from smartphones and logical-layer identification of RFID tags seem more likely — but it’s probably the hardest to defend against. It is possible to disable RFID tags, but this is usually irreversible and it’s difficult to be sure you haven’t missed any. RFID jammers are another option but they are far from easy to use and are probably illegal in the U.S. One of the ETH Zurich researchers suggests tinfoil wrapping when going out shopping :-)

[1] Active RFID chips exist but most commercial systems use passive ones, and that’s what the fingerprinting research has focused on.
[2] They used a population of 50 tags, but this number is largely irrelevant since the experiment was one of binary classification rather than 1-out-of-n identification.
Thanks to Vincent Toubiana for comments on a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
“Do Not Track” Explained
While the debate over online behavioral advertising and tracking has been going on for several years, it has recently intensified due to media coverage — for example, the Wall Street Journal What They Know series — and congressional and senate attention. The problems are clear; what can be done? Since purely technological solutions don’t seem to exist, it is time to consider legislative remedies.
One of the simplest and potentially most effective proposals is Do Not Track (DNT) which would give users a way to opt out of behavioral tracking universally. It is a way to move past the arms race between tracking technologies and defense mechanisms, focusing on the actions of the trackers rather than their tools. A variety of consumer groups and civil liberties organizations have expressed support for Do Not Track; Jon Leibowitz, chairman of the Federal Trade Comission has also indicated that DNT is on the agency’s radar.
Not a list. While Do Not Track is named in analogy to the Do Not Call registry, and the two are similar in spirit, they are very different in implementation. Early DNT proposals envisaged a registry of users, or a registry of tracking domains; both are needlessly complicated.
The user-registry approach has various shortcomings, at least one of which is fatal: there are no universally recognized user identifiers in use on the Web. Tracking is based on ad-hoc identification mechanisms, including cookies, that the ad networks deploy; by mandating a global, robust identifer, a user registry would in one sense exacerbate the very problem it attempts to solve. It also allows for little flexibility in allowing the user to configure DNT on a site-by-site basis.
The domain-registry approach involves mandating ad networks to register domains used for tracking with a central authority. Users would have the ability to download this list of domains and configure their browser to block them. This strategy has multiple problems, including: (i) the centralization required makes it fickle (ii) it is not clear how to block tracking domains without blocking ads altogether, since displaying an ad requires contacting the server that hosts it and (iii) it requires a level of consumer vigilance that is unreasonable to expect — for example, making sure that the domain list is kept up-to-date by every piece of installed web-enabled software.
The header approach. Today, consensus has been emerging around a far simpler DNT mechanism: have the browser signal to websites the user’s wish to opt out of tracking, specifially, via a HTTP header, such as “X-Do-Not-Track”. The header is sent out with every web request — this includes the page the user wishes to view, as well as each of the objects and scripts embedded within the page, including ads and trackers. It is trivial to implement in the web browser — indeed, there is already a Firefox add-on that implements a such a header.
The header-based approach also has the advantage of requiring no centralization or persistence. But in order for it to be meaningful, advertisers will have to respect the user’s preference not to be tracked. How would this be enforced? There is a spectrum of possibilities, ranging from self-regulation via the Network Advertising Initiative, to supervised self-regulation or “co-regulation,” to direct regulation.
At the very least, by standardizing the mechanism and meaning of opt-out, the DNT header promises a greatly simplified way for users to opt-out compared to the current cookie mechanism. Opt-out cookies are not robust, they are not supported by all ad networks, and are interpreted variously by those that do (no tracking vs. no behavioral advertising). The DNT header avoids these limitations and is also future-proof, in that a newly emergent ad network requires no new user action.
In the rest of this article, I will discuss the technical aspects of the header-based Do Not Track proposal. I will discuss four issues: the danger of a tiered web, how to define tracking, detecting violations, and finally user-empowerment tools. Throughout this discussion I will make a conceptual distinction between content providers or publishers (2nd party) and ad networks (3rd party).
Tiered web. Harlan Yu has raised a concern that DNT will lead to a tiered web in which sites will require users to disable DNT to access certain features or content. This type of restriction, if widespread, could substantially undermine the effectiveness of DNT.
There are two questions to address here: how likely is it that DNT will lead to a tiered web, and what, if anything, should be done to prevent it. The latter is a policy question — should DNT regulation prevent sites from tiering service — so I will restrict myself to the former.
Examining ad blocking allows us to predict how publishers, whether acting by themselves or due to pressure from advertisers, might react to DNT. From the user’s perspective, assuming DNT is implemented as a browser plug-in, ad blocking and DNT would be equivalent to install and, as necessary, disable for certain sites. And from the site’s perspective, ad blocking would result in a far greater decline in revenue than merely preventing behavioral ads. We should therefore expect that DNT will be at least as well tolerated by websites as ad blocking.
This is encouraging, since there are very few mainstream sites today that refuse to serve content to visitors with ad blocking enabled. Ad blocking is quite popular (indeed, the most popular extensions for both Firefox and Chrome are ad blockers). A few sites have experimented with tiering for ad-blocking users, but soon after rescinded due to user backlash. Public perception is a another factor that is likely to skew things even further in favor of DNT being well-tolerated: access to content in exchange for watching ads sounds like a much more palatable bargain than access in exchange for giving up privacy.
One might nonetheless speculate what a tiered web might look like if the ad industry, for whatever reason, decided to take a hard stance against DNT. It is once again easy to look to existing technologies, since we already have a tiered web: logged-in vs anonymous browsing. To reiterate, I do not believe that disabling DNT as a requirement for service will become anywhere near as prevalent as logging in as a requirement for service. I bring up login only to make the comforting observation there seems to be a healthy equilibrium between sites that require login always, some of the time, or never.
Defining tracking. It is beyond the scope of this article to give a complete definition of tracking. Any viable definition will necessarily be complex and comprise both technological and policy components. Eliminating loopholes and at the same time avoiding collateral damage — for example, to web analytics or click-fraud detection — will be a tricky proposition. What I will do instead is bring up a list of questions that will need to be addressed by any such definition:
- How are 2nd parties and 3rd parties delineated? Does DNT affect 2nd-party data collection in any manner, or only 3rd parties?
- Are only specific uses of tracking (primarily, targeted advertising) covered, or is all cross-site tracking covered by default, save possibly for specific exceptions?
- Under use-cases covered (i.e., prohibited) under DNT, can 3rd parties collect any individual data at all or should no data be collected? What about aggregate statistical data?
- If individual data can be collected, what categories? How long can it be retained, and for what purposes can it be used?
Detecting violations. The majority of ad networks will likely have an incentive to comply voluntarily with DNT. Nonetheless, it would be useful to build technological tools to detect tracking or behavioral advertising carried out in violation of DNT. It is important to note that since some types of tracking might be permitted by DNT, the tools in question are merely aids to determine when a further investigation is warranted.
There are a variety of passive (“fingerprinting”) and active (“tagging”) techniques to track users. Tagging is trivially detectable, since it requires modifying the state of the browser. As for fingerprinting, everything except for IP address and the user-agent string requires extra API calls and network activity that is in principle detectable. In summary, some crude tracking methods might be able to pass under the radar, while the finer grained and more reliable methods are detectable.
Detection of impermissible behavioral advertising is significantly easier. Intuitively, two users with DNT enabled should see roughly the same distribution of advertisements on the same web page, no matter how different their browsing history. In a single page view, there could be differences due to fluctuating inventories, A/B testing, and randomness, but in the aggregate, two DNT users should see the same ads. The challenge would be in automating as much of this testing process as possible.
User empowerment technologies. As noted earlier, there is already a Firefox add-on that implements a DNT HTTP header. It should be fairly straightforward to create one for each of the other major browsers. If for some reason this were not possible for a specific browser, an HTTP proxy (for instance, based on privoxy) is another viable solution, and it is independent of the browser.
A useful feature for the add-ons would be the ability to enable/disable DNT on a site-by-site basis. This capability could be very powerful, with the caveat that the user-interface needs to be carefully designed to avoid usability problems. The user could choose to allow all trackers on a given 2nd party domain, or allow tracking by a specific 3rd party on all domains, or some combination of these. One might even imagine lists of block/allow rules similar to the Adblock Plus filter lists, reflecting commonly held perceptions of trust.
To prevent fingerprinting, web browsers should attempt to minimize the amount of information leaked by web requests and APIs. There are 3 contexts in which this could be implemented: by default, as part of the existing private browsing mode, or in a new “anonymous browsing mode.” While minimizing information leakage benefits all users, it helps DNT users in particular by making it harder to implement silent tracking mechanisms. Both Mozilla and reportedly the Chrome team are already making serious efforts in this direction, and I would encourage other browser vendors to do the same.
A final avenue for user empowerment that I want to highlight is the possibility of achieving some form of browser history-based targeting without tracking. This gives me an opportunity to plug Adnostic, a Stanford-NYU collaborative effort which was developed with just this motivation. Our whitepaper describes the design as well as a prototype implementation.

This article is the result of several conversations with Jonathan Mayer and Lee Tien, as well as discussions with Peter Eckersley, Sid Stamm, John Mitchell, Dan Boneh and others. Elie Bursztein also deserves thanks for originally bringing DNT to my attention. Any errors, omissions and opinions are my own.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.

