Posts tagged ‘privacy’
One more re-identification demonstration, and then I’m out
What should we do about re-identification? Back when I started this blog in grad school seven years ago, I subtitled it “The end of anonymous data and what to do about it,” anticipating that I’d work on re-identification demonstrations as well as technical and policy solutions. As it turns out, I’ve looked at the former much more often than the latter. That said, my recent paper A Precautionary Approach to Big Data Privacy with Joanna Huey and Ed Felten tackles the “what to do about it” question head-on. We present a comprehensive set of recommendations for policy makers and practitioners.
One more re-identification demonstration, and then I’m out. Overall, I’ve moved on in terms of my research interests to other topics like web privacy and cryptocurrencies. That said, there’s one fairly significant re-identification demonstration I hope to do some time this year. This is something I started in grad school, obtained encouraging preliminary results on, and then put on the back burner. Stay tuned.
Machine learning and re-identification. I’ve argued that the algorithms used in re-identification turn up everywhere in computer science. I’m still interested in these algorithms from this broader perspective. My recent collaboration on de-anonymizing programmers using coding style is a good example. It uses more sophisticated machine learning than most of my earlier work on re-identification, and the potential impact is more in forensics than in privacy.
Privacy and ethical issues in big data. There’s a new set of thorny challenges in big data — privacy-violating inferences, fairness of machine learning, and ethics in general. I’m collaborating with technology ethics scholar Solon Barocas on these topics. Here’s an abstract we wrote recently, just to give you a flavor of what we’re doing:
How to do machine learning ethically
Every now and then, a story about inference goes viral. You may remember the one about Target advertising to customers who were determined to be pregnant based on their shopping patterns. The public reacts by showing deep discomfort about the power of inference and says it’s a violation of privacy. On the other hand, the company in question protests that there was no wrongdoing — after all, they had only collected innocuous information on customers’ purchases and hadn’t revealed that data to anyone else.
This common pattern reveals a deep disconnect between what people seem to care about when they cry privacy foul and the way the protection of privacy is currently operationalized. The idea that companies shouldn’t make inferences based on data they’ve legally and ethically collected might be disturbing and confusing to a data scientist.
And yet, we argue that doing machine learning ethically means accepting and adhering to boundaries on what’s OK to infer or predict about people, as well as how learning algorithms should be designed. We outline several categories of inference that run afoul of privacy norms. Finally, we explain why ethical considerations sometimes need to be built in at the algorithmic level, rather than being left to whoever is deploying the system. While we identify a number of technical challenges that we don’t quite know how to solve yet, we also provide some guidance that will help practitioners avoid these hazards.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Privacy technologies course roundup: Wiki, student projects, HotPETs
In earlier posts about the privacy technologies course I taught at Princeton during Fall 2012, I described how I refuted privacy myths, and presented an annotated syllabus. In this concluding post I will offer some additional tidbits about the course.
Wiki. I referred to a Wiki a few times in my earlier post, and you might wonder what that was about. The course included an online Wiki discussion component, and this was in fact the centerpiece. Students were required to participate in the online discussion of the day’s readings before coming to class. The in-class discussion would use the Wiki discussion as a starting point.
The advantages of this approach are: 1. it gives the instructor a great degree of control in shaping the discussion of each paper, 2. the instructor can more closely monitor individual students’ progress 3. class discussion can focus on particularly tricky and/or contentious points, instead of rehashing the obvious.
Student projects. Students picked a variety of final projects for the class, and on the whole exceeded my expectations. Here are two very different projects, in brief.
Nora Taranto, a History of Science major, wrote a policy paper about the privacy implications of the shift to electronic medical records. Nora writes:
I wrote a paper about the privacy implications of patient-care institutions (in the United States) using electronic medical record (EMR) systems more and more frequently. This topic had particular relevance given the huge number of privacy breaches that occurred in 2012 alone. Meanwhile, there is a simultaneous criticism coming from care providers about the usability of such EMR systems. As such, many different communities—in the information privacy sphere, in the medical community, in the general public, etc.—have many different things to say. But, given the several privacy breaches that occurred within a couple of weeks in April 2012 and together implicated over a million individuals, concerns have been raised in particular about how secure EMR systems are. These concerns are especially worrisome given the federal government’s push for their adoption nationwide beginning in 2009 when the American Recovery and Reinvestment Act granting funds to hospitals explicitly for the purpose of EMR implementation.
So I looked into the benefits and costs of such systems, with a particular slant towards the privacy benefits/costs. Overall, these systems do have a number of protective mechanisms at their disposal, some preventative and others reactive. While these protective barriers are all necessary, they are not sufficient to guarantee the patient his or her privacy rights in the modern day. These protective mechanisms—authentication schemes, encryption, and data logs/anomaly-detection—need to be expanded and further developed to provide an adequate amount of protection for personal health information. While the government is, at the moment, encouraging the adoption of EMR systems for maximal penetration, medical institutions ought to use caution in considering which systems to implement and ought to hold themselves to a higher standard. Moreover, greater regulatory oversight of EMR systems on the market would help institutions maintain this cautious approach.
Abu Saparov, Ajay Roopakalu, and Rafi Shamim, also undergraduates, designed an implemented an alternative to centralized key distribution. They write:
Our project for the course was to create and implement a decentralized public key distribution protocol and show how it could be used. One of the initial goals of our project was to experience first-hand some of the things that made the design of a usable and useful privacy application so hard. Early on in the process, we decided to try to build some type of application that used cryptography to enhance the privacy of communication with friends. Some of the reasons that we chose this general topic were the fact that all of us had experience with network programming and that we thought some of the things that cryptography can achieve are uniquely cool. We were also somewhat motivated by the prospect of using our application to talk with each other and our other friends after we graduate. We eventually gravitated towards two ideas: (1) a completely peer-to-peer chat system that is encrypted from end-to-end, and (2) a “dumb” social network that allows users to share posts that only their friends (and not the server) can see. During the semester, our focus shifted to designing and implementing the underlying key distribution mechanism upon which these two systems could be built.
When we began to flesh out the designs for our two ideas, we realized that the act of retrieving a friend’s public cryptographic keys was the first challenge to solve. Certificate authorities are the most common way to obtain public keys, but require a large degree of trust to be placed in a small number of authorities. Web of Trust is another option, and is completely decentralized, but often proves difficult in practice because of the need for manual key signing. We decided to make our own decentralized protocol that exposes an easily usable API for clients to use in order to obtain public keys. Our protocol defines an overlay network that features regular nodes, as well as supernodes that are able to prove their trustworthiness, although the details of this are controllable through a policy delegate. The idea is for supernodes to share the task of remembering and verifying public keys through a majority vote of neighboring supernodes. Users running other nodes can ask the supernodes for a friend’s public key. In order to trick someone, an adversary would have to control over half of the supernodes from which a user requested a key. Our decision to go with an overlay network created a variety of issues such as synchronizing information between supernodes, being able to detect and report malicious supernodes, and getting new nodes incorporated into the network. These and the countless other design problems we faced definitely allowed us to appreciate the difficulty of writing a privacy application, but unfortunately, we were not fully able to test every element of our protocol and its implementation. After creating the protocol, we implemented small, bare-bones applications for our initial ideas of peer-to-peer chat and an encrypted social network.
Master’s students Chris Eubank, Marcela Melara, and Diego Perez-Botero did a project on mobile web tracking which, with some further work, turned into a research paper that Chris will speak about at W2SP tomorrow.
Finally, I’m happy to say that I will be discussing the syllabus and my experiences teaching this class at HotPETs this year, in Bloomington, IN, in July.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
What Happened to the Crypto Dream? Now in a new and improved paper form!
Last October I gave a talk titled “What Happened to the Crypto Dream?” where I looked at why crypto seems to have done little for personal privacy. The reaction from the audience (physical and online) was quite encouraging — not that everyone agreed, but they seemed to find it thought provoking — and several people asked me if I’d turn it into a paper. So when Prof. Alessandro Acquisti invited me to contribute an essay to the “On the Horizon” column in IEEE S&P magazine, I jumped at the chance, and suggested this topic.
Thanks to some fantastic feedback from colleagues and many improvements to the prose by the editors, I’m happy with how the essay has turned out. Here it is in two parts: Part 1, Part 2.
While I’m not saying anything earth shaking, I do make a somewhat nuanced argument — I distinguish between “crypto for security” and “crypto for privacy,” and further subdivide the latter into a spectrum between what I call “Cypherpunk Crypto” and “Pragmatic Crypto.” I identify different practical impediments that apply to those two flavors (in the latter case, a complex of related factors), and lay out a few avenues for action that can help privacy-enhancing crypto move in a direction more relevant to practice.
I’m aware that this is a contentious topic, especially since some people feel that the time is ripe for a resurgence of the cypherpunk vision. I’m happy to hear your reactions.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
Privacy technologies: An annotated syllabus
Last semester I taught a course on privacy technologies here at Princeton. Earlier I discussed how I refuted privacy myths that students brought into class. In this post I’d like to discuss the contents of the course. I hope it will be useful to other instructors who are interested in teaching this topic as well as for students undertaking self-study of privacy technologies. Beware: this post is quite long.
What should be taught in a class on privacy technologies? Before we answer that, let’s take a step back and ask, how does one go about figuring out what should be taught in any class?
I’ve seen two approaches. The traditional, default, overwhelmingly common approach is to think of it in terms of “covering content” without much consideration to what students are getting out of it. The content that’s deemed relevant is often determined by what the fashionable research areas happen to be, or historical accident, or some combination thereof.
A contrasting approach, promoted by authors like Bain, applies a laser focus on skills that students will acquire and how they will apply them later in life. On teaching orientation day at Princeton, our instructor, who clearly subscribed to this approach, had each professor describe what students would do in the class they are teaching, then wrote down only the verbs from these descriptions. The point was that our thinking had to be centered around skills that students would take home.
I prefer a middle ground. It should be apparent from my description of the traditional approach above that I’m not a fan. On the other hand, I have to wonder what skills our teaching coach would have suggested for a course on cosmology — avoiding falling into black holes? Alright, I’m exaggerating to make a point. The verbs in question are words like “synthesize” and “evaluate,” so there would be no particular difficulty in applying them to cosmology. But my point is that in a cosmology course, I’m not sure the instructor should start from these verbs.
Sometimes we want students to be exposed to knowledge primarily because it is beautiful, and being able to perceive that beauty inspires us, instills us with a love of further learning, and I dare say satisfies a fundamental need. To me a lot of the crypto “magic” that goes into privacy technologies falls into that category (not that it doesn’t have practical applications).
With that caveat, however, I agree with the emphasis on skills and life impact. I thought of my students primarily as developers of privacy technologies (and more generally, of technological systems that incorporate privacy considerations), but also as users and scholars of privacy technologies.
I organized the course into sections, a short introductory section followed by five sections that alternated in the level of math/technical depth. Every time we studied a technology, we also discussed its social/economic/political aspects. I had a great deal of discretion in guiding where the conversation around the papers went by giving them questions/prompts on the class Wiki. Let us now jump in. The italicized text is from the course page, the rest is my annotation.
0. Intro
Goals of this section: Why are we here? Who cares about privacy? What might the future look like?
- Dan Solove. Why Privacy Matters Even if You Have ‘Nothing to Hide’ (Chronicle)
- David Brin. The Transparent Society (WIRED, circa 1996, later expanded into a book)
In addition to helping flesh out the foundational assumptions of this course that I discussed in the previous post, pairing these opposing views with each other helped make the point that there are few absolutes in this class, that privacy scholars may disagree with each other, and that the instructor doesn’t necessarily agree with the viewpoints in the assigned reading, much less expects students to.
1. Cryptography: power and limitations
Goals. Travel back in time to the 80s and early 90s, understand the often-euphoric vision that many crypto pioneers and hobbyists had for the impact it would have. Understand how cryptographic building blocks were thought to be able to support this restructuring of society. Reason about why it didn’t happen.
Understand the motivations and mathematical underpinnings of the modern research on privacy-preserving computations. Experiment with various encryption tools, discover usability problems and other limitations of crypto.
- David Chaum. Security without Identification: Card Computers to make Big Brother Obsolete (1985)
- Steven Levy. Crypto Rebels (WIRED, 1993; later a 2001 book)
- Eric Hughes. A cypherpunk’s manifesto. (short essay, 1993.)
I think the Chaum paper is a phenomenal and underutilized resource for teaching. My goal was to really immerse students in an alternate reality where the legal underpinnings of commerce were replaced by cryptography, much as Chaum envisioned (and even going beyond that). I created a couple of e-commerce scenarios for Wiki discussion and had them reason about how various functions would be accomplished.
My own views on this topic are set forth in this talk (now a paper; coming soon). In general I aimed to shield students from my viewpoints, and saw my role as helping them discover (and be able to defend) their own. At least in this instance I succeeded. Some students took the position that the cypherpunk dream is just around the corner.
- The ‘Garbled Circuit Protocol’ (Yao’s theorem on secure two-party computation) and its implications (lecture)
This is one of the topics that sadly suffers from a lack of good expository material, so I instead lectured on it.
- Alma Whitten and Doug Tygar. Why Johnny Can’t Encrypt: A Usability Evaluation of PGP 5.0
- Nikita Borisov, Ian Goldberg, Eric Brewer. Off-the-Record Communication, or, Why Not To Use PGP
- Thomas Ptacek. Javascript Cryptography Considered Harmful
One of the exercises here was to install and use various crypto tools and rediscover the usability problems. The difficulties were even worse than I’d anticipated.
2. Data collection and data mining, economics of personal data, behavioral economics of privacy
Goals. Jump forward in time to the present day and immerse ourselves in the world of ubiquitous data collection and surveillance. Discover what kinds of data collection and data mining are going on, and why. Discuss how and why the conversation has shifted from Government surveillance to data collection by private companies in the last 20 years.
Theme: first-party data collection.
- New York Times. How Companies Learn Your Secrets
- Andrew Odlyzko. Privacy, Economics, and Price Discrimination on the Internet
Theme: third-party data collection.
- Julia Angwin. The Web’s New Gold Mine: Your Secrets (First in the Wall Street Journal’s What They Know series)
- Jonathan R. Mayer and John C. Mitchell. Third-Party Web Tracking: Policy and Technology
Theme: why companies act the way they do.
- Joseph Bonneau and Sören Preibusch. The Privacy Jungle: On the Market for Data Protection in Social Networks
- Bruce Schneier. How Security Companies Sucker Us With Lemons (WIRED)
Theme: why people act the way they do.
- Alessandro Acquisti and Jens Grossklags. What Can Behavioral Economics Teach Us About Privacy?
- Alessandro Acquisti. Privacy in Electronic Commerce and the Economics of Immediate Gratification
This section is rather self-explanatory. After the math-y flavor of the first section, this one has a good amount of economics, behavioral economics, and policy. One of the thought exercises was to project current trends into the future and imagine what ubiquitous tracking might lead to in five or ten years.
3. Anonymity and De-anonymization
Important note: communications anonymity (e.g., Tor) and data anonymity/de-anonymization (e.g., identifying people in digital databases) are technically very different, but we will discuss them together because they raise some of the same ethical questions. Also, Bitcoin lies somewhere in between the two.
- Roger Dingledine, Nick Mathewson, Paul Syverson. Tor: The Second-Generation Onion Router
- Satoshi Nakamoto. Bitcoin: A Peer-to-Peer Electronic Cash System
Tor and Bitcoin (especially the latter) were the hardest but also the most rewarding parts of the class, both for them and for me. Together they took up 4 classes. Bitcoin is extremely challenging to teach because it is technically intricate, the ecosystem is rapidly changing, and a lot of the information is in random blog/forum posts.
In a way, I was betting on Bitcoin by deciding to teach it — if it had died with a whimper, their knowledge of it would be much less relevant. In general I think instructors should choose to make these such bets more often; most curricula are very conservative. I’m glad I did.
- Nils Homer at al. Resolving Individuals Contributing Trace Amounts of DNA to Highly Complex Mixtures Using High-Density SNP Genotyping Microarrays
- [Optional] Arvind Narayanan, Elaine Shi, Benjamin I. P. Rubinstein. Link Prediction by De-anonymization: How We Won the Kaggle Social Network Challenge
It was a challenge to figure out which deanonymization paper to assign. I went with the DNA one because I wanted them to see that deanonymization isn’t a fact about data, but a fact about the world. Another thing I liked about this paper is that they’d have to extract the not-too-complex statistical methodology in this paper from the bioinformatics discussion in which it is embedded. This didn’t go as well as I’d hoped.
I’ve co-authored a few deanonymization papers, but they’re not very well written and/or are poorly suited for pedagogical purposes. The Kaggle paper is one exception, which I made optional.
- Paul Ohm. Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization
- [Optional] Jane Yakowitz Bambauer. Tragedy of the Data Commons
This is another pair of papers with opposing views. Since the latter paper is optional, knowing that most of them wouldn’t have read it, I used the Wiki prompts to raise many of the issues that the author raises.
4. Lightweight Privacy Technologies and New Approaches to Information Privacy
While cryptography is the mechanism of choice for cypherpunk privacy and anonymity tools like Tor, it is too heavy a weapon in other contexts like social networking. In the latter context, it’s not so much users deploying privacy tools to protect themselves against all-powerful adversaries but rather a service provider attempting to cater to a more nuanced understanding of privacy that users bring to the system. The goal of this section is to consider a diverse spectrum of ideas applicable to this latter scenario that have been proposed in recent years in the fields of CS, HCI, law, and more. The technologies here are “lightweight” in comparison to cryptographic tools like Tor.
- Scott Lederer, Jason Hong et al. Personal Privacy through Understanding and Action: Five Pitfalls for Designers
- Franziska Roesner et al. User-Driven Access Control: Rethinking Permission Granting in Modern Operating Systems
- Fred Stutzman and Woodrow Hartzog. Obscurity by Design: An Approach to Building Privacy into Social Media
- Woodrow Hartzog and Fred Stutzman. The Case for Online Obscurity
- Jerry Kang et al. Self-surveillance Privacy
- [Optional] Ryan Calo. Against Notice Skepticism In Privacy (And Elsewhere)
- Helen Nissenbaum. A Contextual Approach to Privacy Online
5. Purely technological approaches revisited
This final section doesn’t have a coherent theme (and I admitted as much in class). My goal with the first two papers was to contrast a privacy problem which seems amenable to a purely or primarily technological formulation and solution (statistical queries over databases of sensitive personal information) with one where such attempts have been less successful (the decentralized, own-your-data approach to social networking and e-commerce).
- Differential Privacy. (Lecture)
- Cynthia Dwork. Differential Privacy.
Differential privacy is another topic that is sorely lacking in expository material, especially from the point of view of students who’ve never done crypto before. So this was again a lecture.
- Arvind Narayanan et al. A Critical Look at Decentralized Personal Data Architectures
- John Perry Barlow A Declaration of the Independence of Cyberspace (short essay, 1996)
- James Grimmelmann. Sealand, HavenCo, and the Rule of Law
These two essays aren’t directly related to privacy. One of the recurring threads in this course is the debate between purely technological and legal or other approaches to privacy; the theme here is to generalize it to a context broader than privacy. The Barlow essay asserts the exceptionalism of Cyberspace as an unregulable medium, whereas the Grimmelmann paper provides a much more nuanced view of the relationship between the law and new technological frontiers.
I’m making available the entire set of Wiki discussion prompts for the class (HTML/PDF). I consider this integral to the syllabus, for it shapes the discussion very significantly. I really hope other instructors and students find this useful as a teaching/study guide. For reference, each set of prompts (one set per class) took me about three hours to write on average.
There are many more things I want to share about this class: the major take-home ideas, the rationale for the Wiki discussion format, the feedback I got from students, a description of a couple of student projects, some thoughts on the sociology of different communities studying privacy and how that impacted the class, and finally, links to similar courses that are being taught elsewhere. I’ll probably close this series with a round-up post including as many of the above topics as I can.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
How I utilized “expectation failure” to refute privacy myths
Last semester I taught a course on privacy technologies. Since it was a seminar, the class was a small, self-selected group of very motivated students. Based on the feedback, it seems to have been a success; it was certainly quite personally gratifying for me. This is the first in a series of posts on what I learnt from teaching this course. In this post I will discuss some major misconceptions about privacy, how to refute them, and why it is important to do this right at the beginning of the course.
Privacy’s primary pitfalls
Instructors are often confronted with breaking down faulty mental models that students bring into class before actual learning can happen. This is especially true of the topic at hand. Luckily, misconceptions about privacy are so pervasive in the media and among the general public that it wasn’t too hard to identify the most common ones before the start of the course. And it didn’t take much class discussion to confirm that my students weren’t somehow exempt from these beliefs.
One cluster of myths is about the supposed lack of importance of privacy. 1. “There is no privacy in the digital age.” This is the most common and perhaps the most grotesquely fallacious of the misconceptions; more on this below. 2. “No one cares about privacy any more” (variant: young people don’t care about privacy.) 3. “If you haven’t done anything wrong you have nothing to hide.”
A second cluster of fallacious beliefs is very common among computer scientists and comes from the tendency to reduce everything to a black-and-white technical problem. In this view, privacy maps directly to access control and cryptography is the main technical mechanism for achieving privacy. It’s a view in which the world is full of adversaries and there is no room for obscurity or nontechnical ways of improving privacy.
The first step in learning is to unlearn
Why is it important to spend time confronting faulty mental models? Why not simply teach the “right” ones? In my case, there was a particularly acute reason — to the extent that students believe that privacy is dead and that learning about privacy technologies is unimportant, they are not going to be invested in the class, which would be really bad. But even in the case of misconceptions that don’t lead to students doubting the fundamental premise of the class, there is a surprising reason why unlearning is important.
A famous experiment in the ’80s (I really really recommend reading the linked text) demonstrated what we now know about the ineffectiveness of the “information transmission” model of teaching. The researchers interviewed students after any of four introductory physics courses, and determined that they hadn’t actually learned what had been taught, such as Newton’s laws of motion; instead they just learned to pass the tests. When the researchers sat down with students to find out why, here’s what they found:
What they heard astonished them: many of the students still refused to give up their mistaken ideas about motion. Instead, they argued that the experiment they had just witnessed did not exactly apply to the law of motion in question; it was a special case, or it didn’t quite fit the mistaken theory or law that they held as true.
A special case! Ha. What’s going on here? Well, learning new facts is easy. On the other hand, updating mental models is so cognitively expensive that we go to absurd lengths to avoid doing so. The societal-scale analog of this extreme reluctance is well-illustrated by the history of science — we patched the Ptolemaic model of the Universe, with the Earth at the center, for over a millennium before we were forced to accept that the Copernican system fit observations better.
The instructor’s arsenal
The good news is that the instructor can utilize many effective strategies that fall under the umbrella of active learning. Ken Bain’s excellent book (which the preceding text describing the experiment is from) lays out a pattern in which the instructor creates an expectation failure, a situation in which existing mental models of reality will lead to faulty expectations. One of the prerequisites for this to work, according to the book, is to get students to care.
Bain argues that expectation failure, done right, can be so powerful that students might need emotional support to cope. Fortunately, this wasn’t necessary in my class, but I have no doubt of it based on my personal experiences. For instance, back when I was in high school, learning how the Internet actually worked and realizing that my intuitions about the network had to be discarded entirely was such a disturbing experience that I remember my feelings to this day.
Let’s look at an example of expectation failure in my privacy class. To refute the “privacy is dying” myth, I found it useful to talk about Fifty Shades of Grey — specifically, why it succeeded even though publishers initially passed on it. One answer seems to be that since it was first self-published as an e-book, it allowed readers to be discreet and avoid the stigma associated with the genre. (But following its runaway success in that form, the stigma disappeared, and it was released in paper form and flew off the shelves.)
The relative privacy of e-books from prying strangers is one of the many ways in which digital technology affords more privacy for specific activities. Confronting students with an observed phenomenon whose explanation involves a fact that seems starkly contrary to the popular narrative creates an expectation failure. Telling personal stories about how technology has either improved or eroded privacy, and eliciting such stories from students, gets them to care. Once this has been accomplished, it’s productive to get into a nuanced discussion of how to reconcile the two views with each other, different meanings of privacy (e.g., tracking of reading habits), how the Internet has affected each, and how society is adjusting to the changing technological landscape.
I’m quite new to teaching — this is only my second semester at Princeton — but it’s been exciting to internalize the fact that learning is something that can be studied scientifically and teaching is an activity that can vary dramatically in effectiveness. I’m looking forward to getting better at it and experimenting with different methods. In the next post I will share some thoughts on the content of my course and what I tried to get students to take home from it.
Thanks to Josh Hug for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
Unlikely Outcomes? A Distributed Discussion on Decentralized Personal Data Architectures
In recent years there has been a mushrooming of decentralized social networks, personal data stores and other such alternatives to the current paradigm of centralized services. In the academic paper A Critical Look at Decentralized Personal Data Architectures last year, my coauthors and I challenged the feasibility and desirability of these alternatives (I also gave a talk about this work). Based on the feedback, we realized it would be useful to explicate some of our assumptions and implicit viewpoints, add context to our work, clarify some points that were unclear, and engage with our critics on some of the more contentious claims.
We found the perfect opportunity to do this via an invitation from Unlike Us Reader, produced by the Institute of Network Cultures — it’s a magazine run by a humanities-oriented group of people, with a long-standing interest in digital culture, but they also attract some politically oriented developers. The Unlike Us conference, from which this edited volume stems, is also very interesting. [1]
Three of the five original authors — Solon, Vincent and I — teamed up with the inimitable Seda Gürses for an interview-style conversation (PDF). Seda is unique among privacy researchers — one of her interests is to understand and reconcile the often maddeningly divergent viewpoints of the different communities that study privacy, so she was the ideal person to play the role of interlocutor. Seda solicited feedback from about two dozen people in the hobbyist, activist and academic communities, and synthesized the responses into major themes. Then the three of us took turns responding to the prompts, which Solon, with Seda’s help, organized into a coherent whole. A majority of the commenters consented to making their feedback public, and Seda has collected the discussion into an online appendix.
This was an unusual opportunity, and I’m grateful to everyone who made it happen, particularly Seda and Solon who put in an immense amount of work. My participation was very enjoyable. Research proceeds at such a pace that we rarely have the opportunity to look back and cogitate about the process; when we do, we’re often surprised by what we find. For example, here’s something I noted with amusement in one of my responses:
My interest in decentralized social networking apparently dates to 2009, as I just discovered by digging through my archives. I’d signed up to give a talk on pitfalls of social networking privacy at a Stanford workshop, and while preparing for it I discovered the rich academic literature and the various hobbyist efforts in the decentralized model. My slides from that talk seem to anticipate several of the points we made about decentralized social networking in the paper (albeit in bullet-point form), along with the conclusion that they were “unlikely to disrupt walled gardens.” Funnily enough, I’d completely forgotten about having given this talk when we were writing the paper.
I would recommend reading this text as a companion to our original paper. Read it for extra context and clarifications, a discussion of controversial points, and as a way of stimulating thinking about the future prospects of alternative architectures. It may also be an interesting read as an example of how people writing an article together can have different views, and as a bit of a behind-the-scenes look at the research process.
[1] In particular, the latest edition of the conference that just concluded had a panel titled “Are you distributed? The Federated Web Show” moderated by Seda, with Vincent as one of the participants. It touched upon many of the same themes as our work.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
Tracking Not Required: Behavioral Targeting
Co-authored by Jonathan Mayer and Subodh Iyengar.
In the first installment of the Tracking Not Required series, we discussed a relatively straightforward case: frequency capping. Now let’s get to the 800-pound gorilla, behaviorally targeted advertising, putatively the main driver of online tracking. We will show how to swap a little functionality for a lot of privacy.
Admittedly, implementing behavioral targeting on the client is hard and will require some technical wizardry. It doesn’t come for “free” in that it requires a trade-off in terms of various privacy and deployability desiderata. Fortunately, this has been a fertile topic of research over the past several years, and there are papers describing solutions at a variety of points on the privacy-deployability spectrum. This post will survey these papers, and propose a simplification of the Adnostic approach — along with prototype code — that offers significant privacy and is straightforward to implement.
Goals. Carrying out behavioral advertising without tracking requires several things. First, the user needs to be profiled and categorized based on their browsing history. In nearly all proposed solutions, this happens in the user’s browser. Second, we need an algorithm for selecting targeted ads to display each time the user visits a page. If the profile is stored locally and not shared with the advertising company, this is quite nontrivial. The final component is for reporting of ad impressions and clicks. This component must also deal with click fraud, impression fraud and other threats.
Existing approaches
The chart presents an overview of existing and proposed architectures.
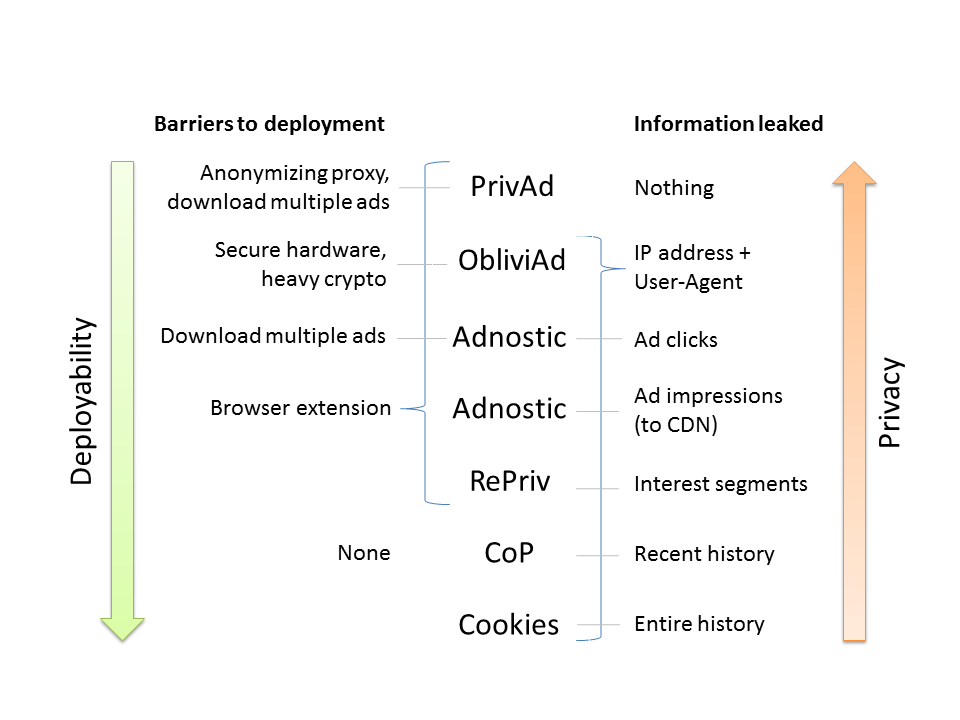
“Cookies” refers to the status quo of server-side tracking; all other architectures are presented in research papers summarized in the Do Not Track bibliography page. CoP stands for “Client-only Profiles,” the architecture proposed by Bilenko and Richardson.
Several points of note. First, everything except PrivAd — which uses an anonymizing proxy — reveals the IP address, and typically the User Agent and Referer to the ad company as part of normal HTTP requests. Second, everything except CoP (and the status quo of tracking cookies) requires software installation. Opinions vary on just how much of a barrier this is. Third, we don’t take a stance on whether PrivAd is more deployable than ObliviAd or vice-versa; they both face significant hurdles. Finally, Adnostic can be used in one of two modes, hence it is listed twice.
There is an interesting technological approach, not listed above, that works by exposing more limited referer information. Without the referer header (or an equivalent), the ad server may identify the user but will not learn the first-party URL, and thus will not be able to track. This will be explored in more depth in a future article.
New approach. In the solution we propose here, the server is recruited for profiling, but doesn’t store the profile. This avoids the need for software installation and allows easy deployability. In addition, non-tracking is externally verifiable, to the extent that IP address + User-Agent is not nearly as effective for tracking as cookie-based unique identifiers.[1] Like CoP, and unlike Adnostic, each ad company can only profile users during visits to pages that it has a third-party presence on, rather than all pages.
Profiling algorithm.
1. The user visits a page that has embedded content from the ad company.
2. JavaScript in the ad company’s content sends the top-level URL to a special classifier service run by the ad company. (The classifier is run on a separate domain. It does not have any cookies or other information specific to the user.)
3. The classifier returns a topic classification of the page.
4. The ad company’s JavaScript receives the page classification and uses it to update the user’s behavioral profile in HTML5 storage. The JavaScript may also consider other factors, such as how long the user stayed on the page.
There is a fair degree of flexibility in steps 3 and 4 — essentially any profiling algorithm can be implemented by appropriately splitting it into a server-side component that classifies individual web pages and a client-side component that analyzes the user’s interaction with these pages.
Ad serving and accounting.
The ad serving process in our proposal is the same as in Adnostic — the server sends a list of ads along with metadata describing each ad, and the client-side component picks the ad that best matches the locally stored profile. To avoid revealing which ad was displayed, the client can either download all (say, 10) ads in the list while displaying only one, or the client downloads only one ad, but ads are served from a different domain which does not share cookies with the tracking domain. Note the similarity to our frequency capping approach, both in terms of the algorithm and its privacy properties.
Accounting, i.e., billing the right advertiser is also identical to Adnostic for the cost-per-click and cost-per-impression models; we refer the reader there. Discussing the cost-per-action model is deferred to a future post.
Implementation. We implemented our behavioral targeting algorithm using HTML 5 local storage. As with our frequency capping implementation, we found performance was exceptionally fast in modern desktop and mobile browsers. For simplicity, our implementation uses a static local database mapping websites to interest segments and a binary threshold for determining interests. In practice, we expect implementers would maintain the mapping server-side and apply more sophisticated logic client-side.
We also present a different work-in-progress implementation that’s broader in scope, encompassing retargeting, behavioral targeting and frequency capping.
Conclusion. Certainly there are costs to our approach — a “thick-client” model will always be slightly more inconvenient to deploy and maintain than a server-based model, and will probably have a lower targeting accuracy. However, we view these costs as minimal compared to the benefits. Some compromise is necessary to get past the current stalemate in web tracking.
Technological feasibility is necessary, but not sufficient, to change the status quo in online tracking. The other key component is incentives. That is why Do Not Track, standards and advocacy are crucial to the online privacy equation.
[1] The engineering and business reasons for this difference in effectiveness will be discussed in a future post.
To stay on top of future posts, subscribe to the RSS feed or follow me on Google+.
Web Privacy Measurement: Genesis of a Community
Last week I participated in the Web Privacy Measurement conference at Berkeley. It was a unique event because the community is quite new and this was our very first gathering. The WSJ Data Transparency hackathon is closely related; the Berkeley conference can be thought of as an academic counterpart. So it was doubly fascinating for me — both for the content and because of my interest in the sociology of research communities.
A year ago I explained that there is an information asymmetry when it comes to online privacy, leading to a “market for lemons.” The asymmetry exists for two main reasons: one is that companies don’t disclose what data they collect about you and what they do with it; the second is that even if they do, end users don’t have the capacity to aggregate and process that information and make decisions on the basis of it.
The Web Privacy Measurement community essentially exists to mitigate this asymmetry. The primary goal is to ferret out what is happening to your data online, and a secondary one is making this information useful by pushing for change, building tools for opt-out and control, comparison of different players, etc. The size of the community is an indication of how big the problem has gotten.
Before anyone starts trotting out the old line, “see, the market can solve everything!”, let me point out that the event schedule demonstrates, if anything, the opposite. The majority of what is produced here is intended wholly or partly for the consumption of regulators. Like many others, I found the “What privacy measurement is useful for policymakers?” panel to be the most interesting one. And let’s not forget that most of this is Government-funded research to begin with.
This community is very different from the others that I’ve belonged to. The mix of backgrounds is extraordinary: researchers mainly from computing and law, and a small number from other disciplines. Most of the researchers are academics, but a few work for industrial research labs, a couple are independent, and one or two work in Government. There were also people from companies that make privacy-focused products/services, lawyers, hobbyists, scholars in the humanities, and ad-industry representatives. Overall, the community has a moderately adversarial relationship with industry, naturally, and a positive relationship with the press, regulators and privacy advocates.
The make-up is somewhat similar to the (looser-knit) group of researchers and developers building decentralized architectures for personal data, a direction that my coauthors and I have taken a skeptical view of in this recent paper. In both cases, the raison d’être of the community is to correct the imbalance of power between corporations and the public. There is even some overlap between the two groups of people.
The big difference is that the decentralization community, typified by Diaspora, mostly tries to mount a direct challenge and overthrow the existing order, whereas our community is content to poke, measure, and expose, and hand over our findings to regulators and other interested parties. So our potential upside is lower — we’re not trying to put a stop to online tracking, for example — but the chance that we’ll succeed in our goals is much higher.
Exciting times. I’m curious to see how things evolve. But this week I’m headed to PLSC, which remains my favorite privacy-related conference.
Thanks to Aleecia McDonald for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Google+.
A Critical Look at Decentralized Personal Data Architectures
I have a new paper with the above title, currently under peer review, with Vincent Toubiana, Solon Barocas, Helen Nissenbaum and Dan Boneh (the Adnostic gang). We argue that distributed social networking, personal data stores, vendor relationship management, etc. — movements that we see as closely related in spirit, and which we collectively term “decentralized personal data architectures” — aren’t quite the panacea that they’ve been made out to be.
The paper is only a synopsis of our work so far — in our notes we have over 80 projects, papers and proposals that we’ve studied, so we intend to follow up with a more complete analysis. For now, our goal is to kick off a discussion and give the community something to think about. The paper was a lot of fun to write, and we hope you will enjoy reading it. We recognize that many of our views and conclusions may be controversial, and we welcome comments.
Abstract:
While the Internet was conceived as a decentralized network, the most widely used web applications today tend toward centralization. Control increasingly rests with centralized service providers who, as a consequence, have also amassed unprecedented amounts of data about the behaviors and personalities of individuals.
Developers, regulators, and consumer advocates have looked to alternative decentralized architectures as the natural response to threats posed by these centralized services. The result has been a great variety of solutions that include personal data stores (PDS), infomediaries, Vendor Relationship Management (VRM) systems, and federated and distributed social networks. And yet, for all these efforts, decentralized personal data architectures have seen little adoption.
This position paper attempts to account for these failures, challenging the accepted wisdom in the web community on the feasibility and desirability of these approaches. We start with a historical discussion of the development of various categories of decentralized personal data architectures. Then we survey the main ideas to illustrate the common themes among these efforts. We tease apart the design characteristics of these systems from the social values that they (are intended to) promote. We use this understanding to point out numerous drawbacks of the decentralization paradigm, some inherent and others incidental. We end with recommendations for designers of these systems for working towards goals that are achievable, but perhaps more limited in scope and ambition.
To stay on top of future posts, subscribe to the RSS feed or follow me on Google+.
Is Writing Style Sufficient to Deanonymize Material Posted Online?
I have a new paper appearing at IEEE S&P with Hristo Paskov, Neil Gong, John Bethencourt, Emil Stefanov, Richard Shin and Dawn Song on Internet-scale authorship identification based on stylometry, i.e., analysis of writing style. Stylometric identification exploits the fact that we all have a ‘fingerprint’ based on our stylistic choices and idiosyncrasies with the written word. To quote from my previous post speculating on the possibility of Internet-scale authorship identification:
Consider two words that are nearly interchangeable, say ‘since’ and ‘because’. Different people use the two words in a differing proportion. By comparing the relative frequency of the two words, you get a little bit of information about a person, typically under 1 bit. But by putting together enough of these ‘markers’, you can construct a profile.
The basic idea that people have distinctive writing styles is very well-known and well-understood, and there is an extremely long line of research on this topic. This research began in modern form in the early 1960s when statisticians Mosteller and Wallace determined the authorship of the disputed Federalist papers, and were featured in TIME magazine. It is never easy to make a significant contribution in a heavily studied area. No surprise, then, that my initial blog post was written about three years ago, and the Stanford-Berkeley collaboration began in earnest over two years ago.
Impact. So what exactly did we achieve? Our research has dramatically increased the number of authors that can be distinguished using writing-style analysis: from about 300 to 100,000. More importantly, the accuracy of our algorithms drops off gently as the number of authors increases, so we can be confident that they will continue to perform well as we scale the problem even further. Our work is therefore the first time that stylometry has been shown to have to have serious implications for online anonymity.[1]
Anonymity and free speech have been intertwined throughout history. For example, anonymous discourse was essential to the debates that gave birth to the United States Constitution. Yet a right to anonymity is meaningless if an anonymous author’s identity can be unmasked by adversaries. While there have been many attempts to legally force service providers and other intermediaries to reveal the identity of anonymous users, courts have generally upheld the right to anonymity. But what if authors can be identified based on nothing but a comparison of the content they publish to other web content they have previously authored?
Experiments. Our experimental methodology is set up to directly address this question. Our primary data source was the ICWSM 2009 Spinn3r Blog Dataset, a large collection of blog posts made available to researchers by Spinn3r.com, a provider of blog-related commercial data feeds. To test the identifiability of an author, we remove a random k (typically 3) posts from the corresponding blog and treat it as if those posts are anonymous, and apply our algorithm to try to determine which blog it came from. In these experiments, the labeled (identified) and unlabled (anonymous) texts are drawn from the same context. We call this post-to-blog matching.
In some applications of stylometric authorship recognition, the context for the identified and anonymous text might be the same. This was the case in the famous study of the federalist papers — each author hid his name from some of his papers, but wrote about the same topic. In the blogging scenario, an author might decide to selectively distribute a few particularly sensitive posts anonymously through a different channel. But in other cases, the unlabeled text might be political speech, whereas the only available labeled text by the same author might be a cooking blog, i.e., the labeled and unlabeled text might come from different contexts. Context encompasses much more than topic: the tone might be formal or informal; the author might be in a different mental state (e.g., more emotional) in one context versus the other, etc.
We feel that it is crucial for authorship recognition techniques to be validated in a cross-context setting. Previous work has fallen short in this regard because of the difficulty of finding a suitable dataset. We were able to obtain about 2,000 pairs (and a few triples, etc.) of blogs, each pair written by the same author, by looking at a dataset of 3.5 million Google profiles and searching for users who listed more than one blog in the ‘websites’ field.[2] We are thankful to Daniele Perito for sharing this dataset. We added these blogs to the Spinn3r blog dataset to bring the total to 100,000. Using this data, we performed experiments as follows: remove one of a pair of blogs written by the same author, and use it as unlabeled text. The goal is to find the other blog written by the same author. We call this blog-to-blog matching. Note that although the number of blog pairs is only a few thousand, we match each anonymous blog against all 99,999 other blogs.
Results. Our baseline result is that in the post-to-blog experiments, the author was correctly identified 20% of the time. This means that when our algorithm uses three anonymously published blog posts to rank the possible authors in descending order of probability, the top guess is correct 20% of the time.
But it gets better from there. In 35% of cases, the correct author is one of the top 20 guesses. Why does this matter? Because in practice, algorithmic analysis probably won’t be the only step in authorship recognition, and will instead be used to produce a shortlist for further investigation. A manual examination may incorporate several characteristics that the automated analysis does not, such as choice of topic (our algorithms are scrupulously “topic-free”). Location is another signal that can be used: for example, if we were trying to identify the author of the once-anonymous blog Washingtonienne we’d know that she almost certainly resides in or around Washington, D.C. Alternately, a powerful adversary such as law enforcement may require Blogger, WordPress, or another popular blog host to reveal the login times of the top suspects, which could be correlated with the timing of posts on the anonymous blog to confirm a match.
We can also improve the accuracy significantly over the baseline of 20% for authors for whom we have more than an average number of labeled or unlabeled blog posts. For example, with 40–50 labeled posts to work with (the average is 20 posts per author), the accuracy goes up to 30–35%.
An important capability is confidence estimation, i.e., modifying the algorithm to also output a score reflecting its degree of confidence in the prediction. We measure the efficacy of confidence estimation via the standard machine-learning metrics of precision and recall. We find that we can improve precision from 20% to over 80% with only a halving of recall. In plain English, what these numbers mean is: the algorithm does not always attempt to identify an author, but when it does, it finds the right author 80% of the time. Overall, it identifies 10% (half of 20%) of authors correctly, i.e., 10,000 out of the 100,000 authors in our dataset. Strong as these numbers are, it is important to keep in mind that in a real-life deanonymization attack on a specific target, it is likely that confidence can be greatly improved through methods discussed above — topic, manual inspection, etc.
We confirmed that our techniques work in a cross-context setting (i.e., blog-to-blog experiments), although the accuracy is lower (~12%). Confidence estimation works really well in this setting as well and boosts accuracy to over 50% with a halving of recall. Finally, we also manually verified that in cross-context matching we find pairs of blogs that are hard for humans to match based on topic or writing style; we describe three such pairs in an appendix to the paper. For detailed graphs as well as a variety of other experimental results, see the paper.
We see our results as establishing early lower bounds on the efficacy of large-scale stylometric authorship recognition. Having cracked the scale barrier, we expect accuracy improvements to come easier in the future. In particular, we report experiments in the paper showing that a combination of two very different classifiers works better than either, but there is a lot more mileage to squeeze from this approach, given that ensembles of classifiers are known to work well for most machine-learning problems. Also, there is much work to be done in terms of analyzing which aspects of writing style are preserved across contexts, and using this understanding to improve accuracy in that setting.
Techniques. Now let’s look in more detail at the techniques I’ve hinted at above. The author identification task proceeds in two steps: feature extraction and classification. In the feature extraction stage, we reduce each blog post to a sequence of about 1,200 numerical features (a “feature vector”) that acts as a fingerprint. These features fall into various lexical and grammatical categories. Two example features: the frequency of uppercase words, the number of words that occur exactly once in the text. While we mostly used the same set of features that the authors of the Writeprints paper did, we also came up with a new set of features that involved analyzing the grammatical parse trees of sentences.
An important component of feature extraction is to ensure that our analysis was purely stylistic. We do this in two ways: first, we preprocess the blog posts to filter out signatures, markup, or anything that might not be directly entered by a human. Second, we restrict our features to those that bear little resemblance to the topic of discussion. In particular, our word-based features are limited to stylistic “function words” that we list in an appendix to the paper.
In the classification stage, we algorithmically “learn” a characterization of each author (from the set of feature vectors corresponding to the posts written by that author). Given a set of feature vectors from an unknown author, we use the learned characterizations to decide which author it most likely corresponds to. For example, viewing each feature vector as a point in a high-dimensional space, the learning algorithm might try to find a “hyperplane” that separates the points corresponding to one author from those of every other author, and the decision algorithm might determine, given a set of hyperplanes corresponding to each known author, which hyperplane best separates the unknown author from the rest.
We made several innovations that allowed us to achieve the accuracy levels that we did. First, contrary to some previous authors who hypothesized that only relatively straightforward “lazy” classifiers work for this type of problem, we were able to avoid various pitfalls and use more high-powered machinery. Second, we developed new techniques for confidence estimation, including a measure very similar to “eccentricity” used in the Netflix paper. Third, we developed techniques to improve the performance (speed) of our classifiers, detailed in the paper. This is a research contribution by itself, but it also enabled us to rapidly iterate the development of our algorithms and optimize them.
In an earlier article, I noted that we don’t yet have as rigorous an understanding of deanonymization algorithms as we would like. I see this paper as a significant step in that direction. In my series on fingerprinting, I pointed out that in numerous domains, researchers have considered classification/deanonymization problems with tens of classes, with implications for forensics and security-enhancing applications, but that to explore the privacy-infringing/surveillance applications the methods need to be tweaked to be able to deal with a much larger number of classes. Our work shows how to do that, and we believe that insights from our paper will be generally applicable to numerous problems in the privacy space.
Concluding thoughts. We’ve thrown open the doors for the study of writing-style based deanonymization that can be carried out on an Internet-wide scale, and our research demonstrates that the threat is already real. We believe that our techniques are valuable by themselves as well.
The good news for authors who would like to protect themselves against deanonymization, it appears that manually changing one’s style is enough to throw off these attacks. Developing fully automated methods to hide traces of one’s writing style remains a challenge. For now, few people are aware of the existence of these attacks and defenses; all the sensitive text that has already been anonymously written is also at risk of deanonymization.
[1] A team from Israel have studied authorship recognition with 10,000 authors. While this is interesting and impressive work, and bears some similarities with ours, they do not restrict themselves to stylistic analysis, and therefore the method is comparatively limited in scope. Incidentally, they have been in the news recently for some related work.
[2] Although the fraction of users who listed even a single blog in their Google profile was small, there were more than 2,000 users who listed multiple. We did not use the full number that was available.
To stay on top of future posts, subscribe to the RSS feed or follow me on Google+.

