Posts tagged ‘web browsers’
Tracking Not Required: Behavioral Targeting
Co-authored by Jonathan Mayer and Subodh Iyengar.
In the first installment of the Tracking Not Required series, we discussed a relatively straightforward case: frequency capping. Now let’s get to the 800-pound gorilla, behaviorally targeted advertising, putatively the main driver of online tracking. We will show how to swap a little functionality for a lot of privacy.
Admittedly, implementing behavioral targeting on the client is hard and will require some technical wizardry. It doesn’t come for “free” in that it requires a trade-off in terms of various privacy and deployability desiderata. Fortunately, this has been a fertile topic of research over the past several years, and there are papers describing solutions at a variety of points on the privacy-deployability spectrum. This post will survey these papers, and propose a simplification of the Adnostic approach — along with prototype code — that offers significant privacy and is straightforward to implement.
Goals. Carrying out behavioral advertising without tracking requires several things. First, the user needs to be profiled and categorized based on their browsing history. In nearly all proposed solutions, this happens in the user’s browser. Second, we need an algorithm for selecting targeted ads to display each time the user visits a page. If the profile is stored locally and not shared with the advertising company, this is quite nontrivial. The final component is for reporting of ad impressions and clicks. This component must also deal with click fraud, impression fraud and other threats.
Existing approaches
The chart presents an overview of existing and proposed architectures.
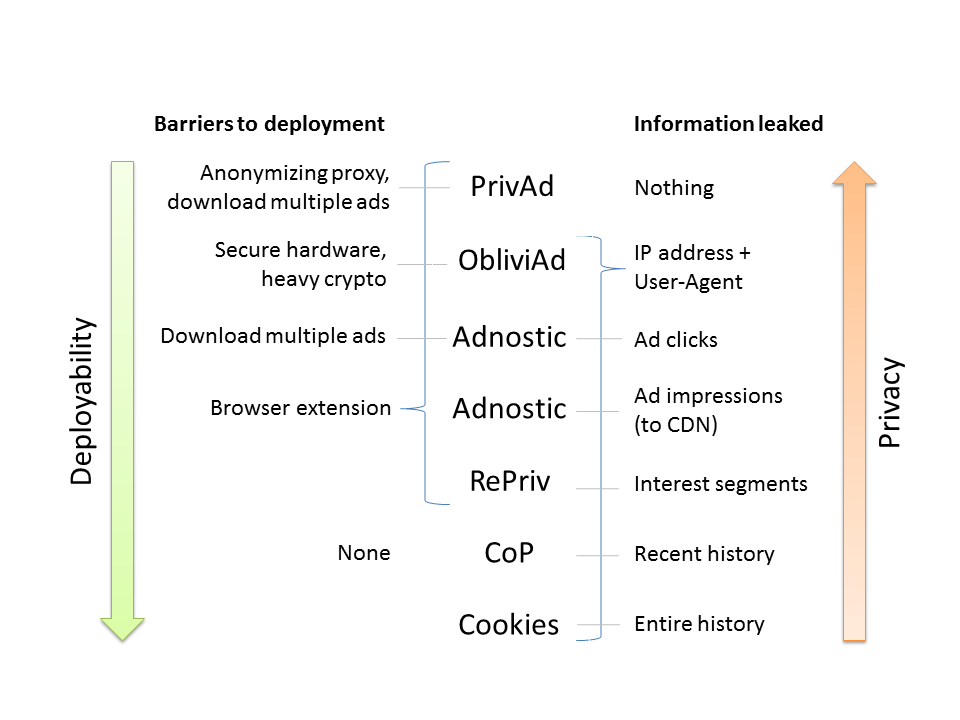
“Cookies” refers to the status quo of server-side tracking; all other architectures are presented in research papers summarized in the Do Not Track bibliography page. CoP stands for “Client-only Profiles,” the architecture proposed by Bilenko and Richardson.
Several points of note. First, everything except PrivAd — which uses an anonymizing proxy — reveals the IP address, and typically the User Agent and Referer to the ad company as part of normal HTTP requests. Second, everything except CoP (and the status quo of tracking cookies) requires software installation. Opinions vary on just how much of a barrier this is. Third, we don’t take a stance on whether PrivAd is more deployable than ObliviAd or vice-versa; they both face significant hurdles. Finally, Adnostic can be used in one of two modes, hence it is listed twice.
There is an interesting technological approach, not listed above, that works by exposing more limited referer information. Without the referer header (or an equivalent), the ad server may identify the user but will not learn the first-party URL, and thus will not be able to track. This will be explored in more depth in a future article.
New approach. In the solution we propose here, the server is recruited for profiling, but doesn’t store the profile. This avoids the need for software installation and allows easy deployability. In addition, non-tracking is externally verifiable, to the extent that IP address + User-Agent is not nearly as effective for tracking as cookie-based unique identifiers.[1] Like CoP, and unlike Adnostic, each ad company can only profile users during visits to pages that it has a third-party presence on, rather than all pages.
Profiling algorithm.
1. The user visits a page that has embedded content from the ad company.
2. JavaScript in the ad company’s content sends the top-level URL to a special classifier service run by the ad company. (The classifier is run on a separate domain. It does not have any cookies or other information specific to the user.)
3. The classifier returns a topic classification of the page.
4. The ad company’s JavaScript receives the page classification and uses it to update the user’s behavioral profile in HTML5 storage. The JavaScript may also consider other factors, such as how long the user stayed on the page.
There is a fair degree of flexibility in steps 3 and 4 — essentially any profiling algorithm can be implemented by appropriately splitting it into a server-side component that classifies individual web pages and a client-side component that analyzes the user’s interaction with these pages.
Ad serving and accounting.
The ad serving process in our proposal is the same as in Adnostic — the server sends a list of ads along with metadata describing each ad, and the client-side component picks the ad that best matches the locally stored profile. To avoid revealing which ad was displayed, the client can either download all (say, 10) ads in the list while displaying only one, or the client downloads only one ad, but ads are served from a different domain which does not share cookies with the tracking domain. Note the similarity to our frequency capping approach, both in terms of the algorithm and its privacy properties.
Accounting, i.e., billing the right advertiser is also identical to Adnostic for the cost-per-click and cost-per-impression models; we refer the reader there. Discussing the cost-per-action model is deferred to a future post.
Implementation. We implemented our behavioral targeting algorithm using HTML 5 local storage. As with our frequency capping implementation, we found performance was exceptionally fast in modern desktop and mobile browsers. For simplicity, our implementation uses a static local database mapping websites to interest segments and a binary threshold for determining interests. In practice, we expect implementers would maintain the mapping server-side and apply more sophisticated logic client-side.
We also present a different work-in-progress implementation that’s broader in scope, encompassing retargeting, behavioral targeting and frequency capping.
Conclusion. Certainly there are costs to our approach — a “thick-client” model will always be slightly more inconvenient to deploy and maintain than a server-based model, and will probably have a lower targeting accuracy. However, we view these costs as minimal compared to the benefits. Some compromise is necessary to get past the current stalemate in web tracking.
Technological feasibility is necessary, but not sufficient, to change the status quo in online tracking. The other key component is incentives. That is why Do Not Track, standards and advocacy are crucial to the online privacy equation.
[1] The engineering and business reasons for this difference in effectiveness will be discussed in a future post.
To stay on top of future posts, subscribe to the RSS feed or follow me on Google+.
“Do Not Track” Explained
While the debate over online behavioral advertising and tracking has been going on for several years, it has recently intensified due to media coverage — for example, the Wall Street Journal What They Know series — and congressional and senate attention. The problems are clear; what can be done? Since purely technological solutions don’t seem to exist, it is time to consider legislative remedies.
One of the simplest and potentially most effective proposals is Do Not Track (DNT) which would give users a way to opt out of behavioral tracking universally. It is a way to move past the arms race between tracking technologies and defense mechanisms, focusing on the actions of the trackers rather than their tools. A variety of consumer groups and civil liberties organizations have expressed support for Do Not Track; Jon Leibowitz, chairman of the Federal Trade Comission has also indicated that DNT is on the agency’s radar.
Not a list. While Do Not Track is named in analogy to the Do Not Call registry, and the two are similar in spirit, they are very different in implementation. Early DNT proposals envisaged a registry of users, or a registry of tracking domains; both are needlessly complicated.
The user-registry approach has various shortcomings, at least one of which is fatal: there are no universally recognized user identifiers in use on the Web. Tracking is based on ad-hoc identification mechanisms, including cookies, that the ad networks deploy; by mandating a global, robust identifer, a user registry would in one sense exacerbate the very problem it attempts to solve. It also allows for little flexibility in allowing the user to configure DNT on a site-by-site basis.
The domain-registry approach involves mandating ad networks to register domains used for tracking with a central authority. Users would have the ability to download this list of domains and configure their browser to block them. This strategy has multiple problems, including: (i) the centralization required makes it fickle (ii) it is not clear how to block tracking domains without blocking ads altogether, since displaying an ad requires contacting the server that hosts it and (iii) it requires a level of consumer vigilance that is unreasonable to expect — for example, making sure that the domain list is kept up-to-date by every piece of installed web-enabled software.
The header approach. Today, consensus has been emerging around a far simpler DNT mechanism: have the browser signal to websites the user’s wish to opt out of tracking, specifially, via a HTTP header, such as “X-Do-Not-Track”. The header is sent out with every web request — this includes the page the user wishes to view, as well as each of the objects and scripts embedded within the page, including ads and trackers. It is trivial to implement in the web browser — indeed, there is already a Firefox add-on that implements a such a header.
The header-based approach also has the advantage of requiring no centralization or persistence. But in order for it to be meaningful, advertisers will have to respect the user’s preference not to be tracked. How would this be enforced? There is a spectrum of possibilities, ranging from self-regulation via the Network Advertising Initiative, to supervised self-regulation or “co-regulation,” to direct regulation.
At the very least, by standardizing the mechanism and meaning of opt-out, the DNT header promises a greatly simplified way for users to opt-out compared to the current cookie mechanism. Opt-out cookies are not robust, they are not supported by all ad networks, and are interpreted variously by those that do (no tracking vs. no behavioral advertising). The DNT header avoids these limitations and is also future-proof, in that a newly emergent ad network requires no new user action.
In the rest of this article, I will discuss the technical aspects of the header-based Do Not Track proposal. I will discuss four issues: the danger of a tiered web, how to define tracking, detecting violations, and finally user-empowerment tools. Throughout this discussion I will make a conceptual distinction between content providers or publishers (2nd party) and ad networks (3rd party).
Tiered web. Harlan Yu has raised a concern that DNT will lead to a tiered web in which sites will require users to disable DNT to access certain features or content. This type of restriction, if widespread, could substantially undermine the effectiveness of DNT.
There are two questions to address here: how likely is it that DNT will lead to a tiered web, and what, if anything, should be done to prevent it. The latter is a policy question — should DNT regulation prevent sites from tiering service — so I will restrict myself to the former.
Examining ad blocking allows us to predict how publishers, whether acting by themselves or due to pressure from advertisers, might react to DNT. From the user’s perspective, assuming DNT is implemented as a browser plug-in, ad blocking and DNT would be equivalent to install and, as necessary, disable for certain sites. And from the site’s perspective, ad blocking would result in a far greater decline in revenue than merely preventing behavioral ads. We should therefore expect that DNT will be at least as well tolerated by websites as ad blocking.
This is encouraging, since there are very few mainstream sites today that refuse to serve content to visitors with ad blocking enabled. Ad blocking is quite popular (indeed, the most popular extensions for both Firefox and Chrome are ad blockers). A few sites have experimented with tiering for ad-blocking users, but soon after rescinded due to user backlash. Public perception is a another factor that is likely to skew things even further in favor of DNT being well-tolerated: access to content in exchange for watching ads sounds like a much more palatable bargain than access in exchange for giving up privacy.
One might nonetheless speculate what a tiered web might look like if the ad industry, for whatever reason, decided to take a hard stance against DNT. It is once again easy to look to existing technologies, since we already have a tiered web: logged-in vs anonymous browsing. To reiterate, I do not believe that disabling DNT as a requirement for service will become anywhere near as prevalent as logging in as a requirement for service. I bring up login only to make the comforting observation there seems to be a healthy equilibrium between sites that require login always, some of the time, or never.
Defining tracking. It is beyond the scope of this article to give a complete definition of tracking. Any viable definition will necessarily be complex and comprise both technological and policy components. Eliminating loopholes and at the same time avoiding collateral damage — for example, to web analytics or click-fraud detection — will be a tricky proposition. What I will do instead is bring up a list of questions that will need to be addressed by any such definition:
- How are 2nd parties and 3rd parties delineated? Does DNT affect 2nd-party data collection in any manner, or only 3rd parties?
- Are only specific uses of tracking (primarily, targeted advertising) covered, or is all cross-site tracking covered by default, save possibly for specific exceptions?
- Under use-cases covered (i.e., prohibited) under DNT, can 3rd parties collect any individual data at all or should no data be collected? What about aggregate statistical data?
- If individual data can be collected, what categories? How long can it be retained, and for what purposes can it be used?
Detecting violations. The majority of ad networks will likely have an incentive to comply voluntarily with DNT. Nonetheless, it would be useful to build technological tools to detect tracking or behavioral advertising carried out in violation of DNT. It is important to note that since some types of tracking might be permitted by DNT, the tools in question are merely aids to determine when a further investigation is warranted.
There are a variety of passive (“fingerprinting”) and active (“tagging”) techniques to track users. Tagging is trivially detectable, since it requires modifying the state of the browser. As for fingerprinting, everything except for IP address and the user-agent string requires extra API calls and network activity that is in principle detectable. In summary, some crude tracking methods might be able to pass under the radar, while the finer grained and more reliable methods are detectable.
Detection of impermissible behavioral advertising is significantly easier. Intuitively, two users with DNT enabled should see roughly the same distribution of advertisements on the same web page, no matter how different their browsing history. In a single page view, there could be differences due to fluctuating inventories, A/B testing, and randomness, but in the aggregate, two DNT users should see the same ads. The challenge would be in automating as much of this testing process as possible.
User empowerment technologies. As noted earlier, there is already a Firefox add-on that implements a DNT HTTP header. It should be fairly straightforward to create one for each of the other major browsers. If for some reason this were not possible for a specific browser, an HTTP proxy (for instance, based on privoxy) is another viable solution, and it is independent of the browser.
A useful feature for the add-ons would be the ability to enable/disable DNT on a site-by-site basis. This capability could be very powerful, with the caveat that the user-interface needs to be carefully designed to avoid usability problems. The user could choose to allow all trackers on a given 2nd party domain, or allow tracking by a specific 3rd party on all domains, or some combination of these. One might even imagine lists of block/allow rules similar to the Adblock Plus filter lists, reflecting commonly held perceptions of trust.
To prevent fingerprinting, web browsers should attempt to minimize the amount of information leaked by web requests and APIs. There are 3 contexts in which this could be implemented: by default, as part of the existing private browsing mode, or in a new “anonymous browsing mode.” While minimizing information leakage benefits all users, it helps DNT users in particular by making it harder to implement silent tracking mechanisms. Both Mozilla and reportedly the Chrome team are already making serious efforts in this direction, and I would encourage other browser vendors to do the same.
A final avenue for user empowerment that I want to highlight is the possibility of achieving some form of browser history-based targeting without tracking. This gives me an opportunity to plug Adnostic, a Stanford-NYU collaborative effort which was developed with just this motivation. Our whitepaper describes the design as well as a prototype implementation.

This article is the result of several conversations with Jonathan Mayer and Lee Tien, as well as discussions with Peter Eckersley, Sid Stamm, John Mitchell, Dan Boneh and others. Elie Bursztein also deserves thanks for originally bringing DNT to my attention. Any errors, omissions and opinions are my own.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Yet Another Identity Stealing Bug. Will Creeping Normalcy be the Result?
Elie Bursztein points me to a “Cross Site URL Hijacking” attack which, among other things, allows a website to identify a visitor instantly (if they are using Firefox) by finding their Google and possibly Facebook IDs. Here is a live demo and here’s a paper.
For the security geeks, the attack works by exploiting a Firefox bug that allows a page in the attacker domain to infer URLs of pages in the target domain. If a page like target.com/home redirects to target.com/?user=[username] (which is quite common), the attacker can learn the username by requesting the page target.com/home in a script tag.
Let us put this attack in context. Stealing the identity of a web visitor should be familiar to readers of this blog. I’ve recently written about doing this via history stealing, then a bug in Google spreadsheets, and now we have this. While the spreadsheets bug was fixed, the history stealing vulnerability remains in most browsers. Will new bugs be found faster than existing ones getting fixed? The answer is probably yes.
Something that is of much more concern in the long run is Facebook’s instant personalization, which is basically like identity stealing, except it is a feature rather than a bug. Currently Facebook identities are available without user consent to only 3 partners (Yelp, Pandora and docs.com) but there will be inevitable competitive pressures both for Facebook to open this up to more websites as well as for other identity providers to offer a similar service.
Legitimate methods and hacks based on bugs are not entirely distinct. Two XSS attacks on yelp.com were found in quick succession either of which could have been exploited by a third (fourth?) party for identity stealing. Instant personalization (and similar attempts at an “identity layer”) greatly increase the chance of bugs that leak your identity to every website, authorized or not.
As identity-stealing bugs as well as identity-sharing features proliferate, the result is going to be creeping normalcy — users will get slowly inured to the idea that any website they visit might have their identity. And that will be a profound change for the way the web works. Of course, savvy users will know how to turn off the various tracking mechanisms, but most people will be left in the lurch.
We are still at the early stages of this shift. It is clear that it will have both good and ill effects. For example, people are much more civil when interacting under their real-life identity. For this reason, there is quite a clamor for identity. For instance, see News Sites Rethink Anonymous Online Comments and The Forces Align Against Anonymity. But like every change, this one is going to be hard to get used to.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Ubercookies Part 2: History Stealing meets the Social Web
Recap. In the previous article I introduced ubercookies — techniques that websites can use to de-anonymize visitors. I discussed a recent paper that shows how to use history stealing along with social network group membership information to find the visitor’s identity, and I promised a stronger variant of the attack.
The observation that led me to the attack I’m going to describe is simple: social networking isn’t just about social networks — the whole web has gone social. It’s a view that you quickly internalize if you spend any time hanging out with Silicon Valley web entrepreneurs :-)
Let’s break the underlying principle of the identity-stealing attack down to its essence:
A user leaves a footprint whenever their interaction with a specific web page is recorded publicly.
De-anonymization happens when the attacker can tie these footprints together into “trails” that can then be correlated with the user’s browser history. Efficiently querying the history to identify multiple points on the trail is a challenging problem to solve, but in principle de-anonymization is possible as long as the user’s actions on different web pages happen under the same identity.
Footprints can be tied together into trails as long as all the interactions happen under the same identity. There is no need for the interactions to be on the same website.
There are two major ways in which you can interact with arbitrary websites under a unified identity, both of which are defining principles of the social web. The first is federated identity, which means you can use the same identity provider wherever you go. This is achieved through OpenID and similar mechanisms like Facebook Connect. The second is social sharing: whenever you find something interesting anywhere on the web, you feed it back to your social network.
Now let’s examine the different types of interactions in more detail.
A taxonomy of interaction on the social web.
0. The pre-social web had no social networks and no delegated identity mechanism (except for the failed attempt by Microsoft called Passport). Users created new identities on each website, authenticated via site-specific usernames and passwords to each site separately. The footprints on different sites cannot be tied together; for practical purposes there are no footprints.

1. Social networks: affiliation. In social networks, users interact with social objects and leave footprints when the actions are public. The key type of interaction that is useful for de-anonymization is the expression of affiliation: this refers to not just the group memberships studied in the recent Wondracek et al. paper, but also includes
- memberships of fan pages on Facebook
- “interests” on Livejournal
- follow relationships and plain old friend relationships on Twitter and other public social networks
- subscriptions to Youtube channels
and so on.
All of these interactions, albeit very different from the user perspective, are fundamentally the same concept:
- you “add yourself” to or affiliate yourself with some object on a social network
- this action can be publicly observed
- you almost certainly visited a URL that identifies the object before adding it.

2. The social web: sharing. When you find a page you like — any page at all — you can import it or “share” it to your social stream, on Facebook, Twitter, Google Buzz, or a social bookmarking site like Delicious. The URL of the page is almost certainly in your history, and as long as your social stream is public, your interaction was recorded publicly.

3. The social web: federated identity. When you’re reading a blog post or article on the social web, you can typically comment on it, “like” it, favorite it, rate it, etc. You do all this under your Facebook, Google or other unified identity. These actions are often public and when they are, your footprint is left on the page.
A taxonomy of attacks
The three types of social interactions above give rise to a neat taxonomy of attacks. They involve progressively easier backend processing and progressively more sophisticated history search techniques on the front end. But the execution time on the front-end doesn’t increase, so it is a net win. Here’s a table:
| Type of interaction |
Backend processing |
Type of history URL |
Location of footprint |
| Affiliation | Crawling of social network | Object in a social network | In the social network |
| Sharing | Syndication of social stream(s) from social network | Any page | In the social network |
| Federated identity | None; optional crawling | Any page | On the page |
.
1. Better use of affiliation information. The Wondracek et al. paper makes use of only group membership. One natural reason to choose groups is that there are many groups that are large, with thousands of members, so it gives us a reasonably high chance that by throwing darts in the browser history we will actually hit a few groups that the user has visited. On the other hand, if we try to use the Facebook friend list, for example, hoping to find one of the user’s friends by random chance, it probably won’t work because most users have only a few hundred friends.
But wait: many Twitter users have thousands or even millions of followers. These are known as “hubs” in network theory. Clearly, the attack will work for any kind of hubs that have predictable URLs, and users on Twitter have even more predictable URLs (twitter.com/username) than groups on various networks. The attack will also work using Youtube favorites (which show up by default on the user’s public profile or channel page) and whatever other types of affiliation we might choose to exploit, as long as there are “hubs” — nodes in the graph with high degree. Already we can see that many more websites are vulnerable than the authors envisaged.
2. Syndicating the social stream: my Delicious experiment.
The interesting thing about the social stream is that you can syndicate the stream of interactions, rather than crawling. The reasons why syndication is much easier than crawling are more practical than theoretical. First, syndicated data is intended to be machine readable, and is therefore smaller as well as easier to parse compared to scraping web pages. Second, and more importantly, you might be to get a feed of the entire site-wide activity instead of syndicating each user’s activity stream separately. Delicious allows global syndication; Twitter plans to open this “firehose” feature to all developers soon.
Another advantage of the social stream is that everything is timestamped, so you can limit yourself to recent interactions, which are more likely to be in the user’s history.
Using the delicious.com dataset made available by DAI-labor (a log of all bookmarking activity on delicious.com over several years), I did a simulated experiment using 3 months worth of data: assuming that users keep their history around for 3 months, do in fact visit every link they post on delicious, how many users would a hypothetical history stealing attack be able to identify? I had a pretty good success rate: about 60% of the users who had shared at least 2 links in the 3-month period, or about 300,000 users. This takes at most 4000-5000 Javascript history queries.
Needless to say, once Twitter opens up its firehose, Twitter users (who are far more numerous than delicious users) would also be susceptible to the same technique.
This attack is not possible to fix via server-side URL randomization. It can also be made to work using Facebook, Google Buzz, and other sharing platforms, although the backend processing required won’t be as trivial (but probably no harder than in the original attack.)
3. A somewhat random walk through the history park.
And now for an approach that potentially requires no backend data collection, although it is speculative and I can’t guess what the success rate would be. The attack proceeds in several steps:
- Identify the user’s interests by testing if they’ve visited various popular topic-specific sites. Pick one of the user’s favorite topics. Incidentally, a commenter on my previous post notes he is building exactly this capability using topic pages on Wikipedia, also with the goal of de-anonymization!
- Grab a list of the top blogs on the topic you picked from one of the blog directories. Query the history to see which of these blogs the user reads frequently. It is even possible to estimate the level of interest in a blogs by looking at the fraction of the top/recent posts from that blog that the user has visited. Pick a blog that the user seems to visit regularly.
- Look for evidence of the user leaving comments on posts. For example, on Blogger, the comment page for a post has the URL http://www.blogger.com/comment.g?blogID=<blogid>&postID=<postid>.
- Once you find a couple of posts where it looks like the user made a comment, scrape the list of people who commented on it, find the intersection. (Even a single comment might suffice; as long as you have a list of candidates, you easily verify if it’s one of them by testing user-specific URLs. More below.)
- Depending on the blogging platform, you might even be able to deduce that the user responded (or intended to respond) to a specific comment. For example, On wordpress you have the pattern http://<blogname>.wordpress.com/<postname>/?replytocom=<commentid>#respond. If you get lucky and find one of those patterns, that makes things even easier.
If at first you don’t succeed, pick a different blog and repeat.
I suspect that the most practical method would be to use a syndicated activity stream from a social network, but also to use the heuristics presented above to more efficiently search through the history.
Epilogue: Identity.
Not only has there been a movement towards a small number of identity providers on the web, there are many aggregators out there that have sprung up in order to automatically find the connections between identities across the different identity providers, and also connect online identities to physical-world databases. As Pete Warden notes:
One of the least-understood developments of the last few years is the growth of databases of personal information linked to email addresses. Rapleaf is probably the leader in this field, but even Flickr lets companies search their API for users based on an email address.
I ran my email address through his demo script and it is quite clear that virtually all of my online identities have been linked together. This is getting to be the norm; as a consequence, once an attacker gets any kind of handle on you, they can go “identity hopping” and find out a whole lot more about you.
This is also the reason that once the attacker can make a reasonable guess at the visitor’s identity, it’s easy to verify the guess. Not only can they look for user-specific URLs in your history to confirm the guess (described in detail in the Wondracek et al. paper), but all your social streams on other sites can also be combined with your history to corroborate your identity.
Up next in the Ubercookies series: So that’s pretty bad. But it’s going to get worse before it can get better :-) In the next article, I will describe an entirely different attack strategy to get at your identity by exploiting a bug in a specific identity provider’s platform.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Cookies, Supercookies and Ubercookies: Stealing the Identity of Web Visitors
 Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Cookies. Most people are aware that their web browsing activity over time and across sites can be tracked using cookies. When you are being tracked, it can be deduced that the same person visited certain sites at certain times, but the sites doing the tracking don’t know who you are, i.e., you name, etc., unless you choose to tell them in some way, such as by logging in.
Cookies are easy to delete, and so there’s been a big impetus in the Internet advertising industry to discover and deploy more robust tracking mechanisms.
Supercookies. You may surprised to find just how helpless a user is against a site (or more usually, a network of sites) that is truly determined to track them. There are Flash cookies, much harder to delete, some of which respawn the regular HTTP cookies that you delete. The EFF’s Panopticlick project demonstrates many “browser fingerprinting” methods which are more sophisticated. (Jonathan Mayer’s senior thesis contained a smaller-scale demonstration of some of those techniques).
A major underlying reason for a lot of these problems is that any browser feature that allows a website to store “state” on the client can be abused for tracking, and there are a bewildering variety of these. There is a great analysis in a paper by my Stanford colleagues. One of the points they make is that co-operative tracking by websites is essentially impossible to defend against.
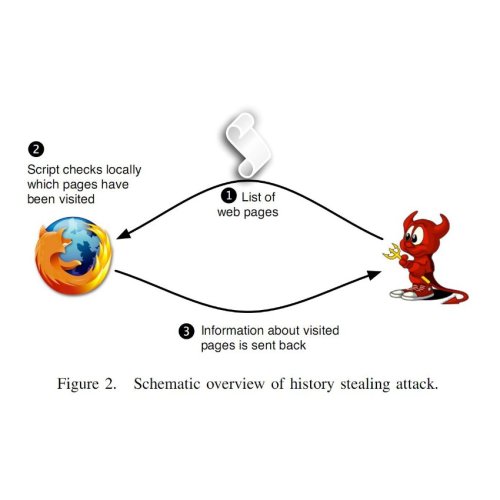
Ubercookies: history stealing. Now let’s get to the scary stuff: uncovering identity. History stealing or history sniffing is an unintended consequence of the way the web is designed; it allows a website to learn which URLs you’ve been to. While a site can’t simply ask your browser for a list of visited URLs, it can ask “yes/no” questions and your browser will faithfully respond. The most common way of doing this is by injecting invisible links into the page using Javascript and exploiting the fact that the CSS link color attribute depends on whether the link has been visited or not.
History stealing has been known for a decade, and browser vendors have failed to fix it because it cannot be fixed without sacrificing some useful functionality (the crude way is to turn off visited link coloring altogether; a subtler solution is SafeHistory). Increasingly worse consequences have been discovered over the years: for example, a malicious site can learn which bank you use and customize a phishing page accordingly. But a paper (full text, PDF) coming out at this year’s IEEE S&P conference at Oakland takes it to a new level.
Identity. Let’s pause for a second and think about what finding your identity means. In the modern, social web, social network accounts have become our de-facto online identities, and most people reveal their name and at least some other real-world information about ourselves on our profiles. So if the attacker can discover the URL of your social network profile, we can agree that he has identified you for all practical purposes. And the new paper shows how to do just that.
The attack relies on the following observations:
- Almost all social networking sites have some kind of “group” functionality: users can add themselves to groups.
- Users typically add themselves to multiple groups, at least some of which are public.
- Group affiliations, just like your movie-watching history and many other types of attributes, are sufficient to fingerprint a user. There’s a high chance there’s no one else who belongs to the same set of groups that you do (or is even close). [Aside: I used this fact to show that Lending Club data can be de-anonymized.]
- Users who belong to a group are likely to visit group-specific URLs that are predictable.
Put the above facts together, and the attack emerges: the attacker (an arbitrary website you visit, without the co-operation of whichever social network is used as an attack enabler) uses history stealing to test a bunch of group-related URLs one by one until he finds a few (public) groups that the anonymous user probably belongs to. The attacker has already crawled the social network, and therefore knows which user belongs to which groups. Now he puts two and two together: using the list of groups he got from the browser, he does a search on the backend to find the (usually unique) user who belongs to all those groups.
Needless to say, this is a somewhat simplified description. The algorithm can be easily modified so that it will work even if some of the groups have disappeared from your history (say because you clear it once in a while) or if you’ve visited groups you’re not a member of. The authors demonstrated that the attack with real users on the Xing network, and also showed theoretically that it is feasible on a number of other social networks including Facebook and Myspace. It takes a few thousand Javascript queries and runs in a few seconds on modern browsers, which makes it pretty much surreptitious.
Fallout. There are only two ways to try to fix this. The first is for all the social networking sites to change their URL patterns by randomizing them so that point 4 above (predictable URL identifying that you belong to a group) is no longer true. The second is for all the browser vendors to fix their browsers so that history stealing is no longer possible.
The authors contacted several of the social networks; Xing quickly implemented the URL randomization fix, which I find surprising and impressive. Ultimately, however, Xing’s move will probably be no more than a nice gesture, for the following reason.
Over the last few days, I have been working on a stronger version of this attack which:
- can make use of every URL in the browser history to try and identify the user. This means that server-side fixes are not possible, because literally every site on the web would need to implement randomization.
- avoids the costly crawling step, further lowering the bar to executing the attack.
That leaves browser-based fixes for history stealing, which hasn’t happened in the 10 years that the problem has been known. Will browsers vendors finally accept the functionality hit and deal with the problem? We can hope so, but it remains to be seen.
In the next article, I will describe the stronger attack and also explain in more detail why your profile page on almost any website is a very strong identifier.
Thanks to Adam Bossy for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.


{kind=link}