Posts tagged ‘ubercookies’
New Developments in Deanonymization
This post is a roundup of developments in deanonymization in the last few months. Let’s start with two stories relating to how a malicious website can silently discover the identity of a visitor, which is an insidious type of privacy breach that I’ve written about quite a bit (1, 2, 3, 4, 5, 6).
Firefox bug exposed your identity. The first is a vulnerability resulting from a Firefox bug in the implementation of functions like exec and test. The bug allows a website to learn the URL of an embedded iframe from some other domain. How can this lead to uncovering the visitor’s identity? Because twitter.com/lists redirects to twitter.com/<username>/lists. This allows a malicious website to open a hidden iframe pointing to twitter.com/lists, query the URL after redirection, and learn the visitor’s Twitter handle (if they are logged in). [1,2]
This is very similar to a previous bug in Firefox that led to the same type of vulnerability. The URL redirect that was exploited there was google.com/profiles/me → user-specific URL. It would be interesting to find and document all such generic-URL → user-specific-URL redirects in major websites. I have a feeling this won’t be the last time such redirection will be exploited.
Visitor deanonymization in the wild. The second story is an example of visitor deanonymization happening in the wild. It appears that the technique utilizes a tracking cookie from a third-party domain to which the visitor previously gave their email and other info., in other words, #3 in my five-fold categorization of ways in which identity can be attached to browsing logs.
I don’t consider this instance to be particularly significant — I’m sure there are other implementations in the wild — and it’s not technically novel, but this is the first time as far as I know that it’s gotten significant attention from the public, even if only in tech circles. I see this as a first step in a feedback loop of changing expectations about online anonymity emboldening more sites to deanonymize visitors, thus further lowering the expectation of privacy.
Deanonymization of mobility traces. Let’s move on to the more traditional scenario of deanonymization of a dataset by combining it with an auxiliary, public dataset which has users’ identities. Srivatsa and Hicks have a new paper with demonstrations of deanonymization of mobility traces, i.e., logs of users’ locations over time. They use public social networks as auxiliary information, based on the insight that pairs of people who are friends are more likely to meet with each other physically. The deanonymization of Bluetooth contact traces of attendees of a conference based on their DBLP co-authorship graph is cute.
This paper adds to the growing body of evidence that anonymization of location traces can be reversed, even if the data is obfuscated by introducing errors (noise).
So many datasets, so little time. Speaking of mobility traces, Jason Baldridge points me to a dataset containing mobility traces (among other things) of 5 million “anonymous” users in the Ivory Coast recently released by telecom operator Orange. A 250-word research proposal is required to get access to the data, which is much better from a privacy perspective than a 1-click download. It introduces some accountability without making it too onerous to get the data.
In general, the incentive for computer science researchers to perform practical demonstrations of deanonymization has diminished drastically. Our goal has always been to showcase new techniques and improve our understanding of what’s possible, and not to name and shame. Even if the Orange dataset were more easily downloadable, I would think that the incentive for deanonymization researchers would be low, now that the Srivatsa and Hicks paper exists and we know for sure that mobility traces can be deanonymized, even though the experiments in the paper are on a far smaller scale.
Head in the sand: rational?! I gave a talk at a privacy workshop recently taking a look back at how companies have reacted to deanonymization research. My main point was that there’s a split between the take-your-data-and-go-home approach (not releasing data because of privacy concerns) and the head-in-the-sand approach (pretending the problem doesn’t exist). Unfortunately but perhaps unsurprisingly, there has been very little willingness to take a middle ground, engaging with data privacy researchers and trying to adopt technically sophisticated solutions.
Interestingly, head-in-the-sand might be rational from companies’ point of view. On the one hand, researchers don’t have the incentive for deanonymization anymore. On the other hand, if malicious entities do it, naturally they won’t talk about it in public, so there will be no PR fallout. Regulators have not been very aggressive in investigating anonymized data releases in the absence of a public outcry, so that may be a negligible risk.
Some have questioned whether deanonymization in the wild is actually happening. I think it’s a bit silly to assume that it isn’t, given the economic incentives. Of course, I can’t prove this and probably never can. No company doing it will publicly talk about it, and the privacy harms are so indirect that tying them to a specific data release is next to impossible. I can only offer anecdotes to explain my position: I have been approached multiple times by organizations who wanted me to deanonymize a database they’d acquired, and I’ve had friends in different industries mention casually that what they do on a daily basis to combine different databases together is essentially deanonymization.
[1] For a discussion of why a social network profile is essentially equivalent to an identity, see here and the epilog here.
[2] Mozilla pulled Firefox 16 as a result and quickly fixed the bug.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter or Google+.
Facebook’s Instant Personalization: An Analysis of Fundamental Privacy Flaws
Facebook has begun to accelerate the web-wide roll-out of the Instant Personalization program. The number of partner websites recently jumped from three to five, and a partnership with early stage venture firm YCombinator is set to greatly expand that number in the coming months.[1]
Instant Personalization allows a partner website to automatically learn the identity of a visitor (as well as some data about them) without any explicit user action, provided that the visitor is a logged-in Facebook user. It is probably the most privacy-intrusive change introduced by the company this year, and could lead to a profound change in how the web works and is perceived.
Facebook’s superficially reassuring line is that only data that is already public is shared with partner sites. Even ignoring the fact that it is hard for users to figure out exactly what data is public, and is only getting harder, I find the official explanation to be a red herring. In this article I will examine the various fundamental flaws of Instant Personalization.
1. Sneakiness. All the information transmitted via Instant Personalization is available via Facebook connect; the sole purpose of Instant Personalization is to eliminate the element of user authorization from the process. Thus, I find the very raison d’etre to be questionable. If a user declines to use Facebook connect, perhaps they had a good reason for doing so. Think about a porn site — I don’t think I need to elaborate.
2. Identity. To me, what is much more worrisome than third parties getting your data is third parties getting your identity when you browse. The idea that a website knows who you are as soon as you land on it is inherently creepy because it violates users’ mental model of how the web works. The cumulative effect is worse — people are intensely uncomfortable when they feel they are being “followed around” as they browse the web.
From a technical perspective, an Instant Personalization partner could itself turn around and become an Instant Personalization provider, and so could any website that this partner provided Instant Personalization services for, ad infinitum. This is because any number of tracking devices (invisible iframes) can be nested within a page.
Implementation bugs on partner sites also have the effect of leaking your identity to other parties. In my ubercookies series, I documented a series of bugs that can be exploited by an arbitrary website to learn the visitor’s identity. All of these apply to Instant Personalization, i.e., if any one of the partner websites has such a bug, that can be exploited by an arbitrary attacker to instantly de-anonymize a visitor to his site. Security researcher theharmonyguy has a great post on cross-site scripting vulnerabilities on both Rotten Tomatoes and Scribd that compromise Instant Personalization in this fashion.[2]
3. Facebook gets your clickstream. Instant Personalization is a two way street: while the partner site gets access to the user’s identity, Facebook learns the URLs of the pages the user visits. In a world where Instant Personalization is widely deployed, Facebook will be able to monitor a large fraction, perhaps the majority, of clicks that you make around the web.
While troubling, this is not unprecedented: the Faceook like button constitutes a very similar privacy problem — Facebook sees you whenever you visit any page with the like button (or another social plugin) installed, even if you don’t click the like button.[3] Facebook bowed to pressure from privacy advocates and agreed to delete the logs from social plugins after 90 days; I would like to see the same policy applied to Instant Personalization logs as well.
4. Third parties could get your clickstream. Normally, an Instant Personalization partner can only see your clicks on their own site. However, think of an Instant Personalization partner whose product is a social widget or an analytics plugin that is intended to be installed on many client sites. From a technical perspective, loading a page or widget in an iframe is not fundamentally different from visiting the site directly. That means it is feasible for an Instant Personalization partner with a social widget to monitor your clicks — tied to your real identity, of course — on all sites with the widget installed.[4]
5. Lack of enforcement. So far I have described the lack of technological barriers to various types of misuse and abuse of Instant Personalization. However, Facebook contractually prohibits partners from misusing the data. The natural question is whether this is effective.
It is too early to tell yet, because there are currently only five partners. To predict how things will turn out once numerous startups — without the resources or incentive for security testing and privacy compliance — get on board, we can look to the track-record of Facebook’s third party application platform. As you may recall, this has been rather poor, with enforcement of Terms of Service violations being haphazard at best.
Mitigation. In my opinion these flaws are inherent, and I don’t think Instant Personalization will turn out well from a security and privacy perspective. User expectations are not malleable, cross-site scripting bugs will always exist, there will soon be too many partner sites to monitor closely, and some of them will look for ways to push the boundaries of what they can do.

However, there are two things Facebook can do to mitigate the extent of the damage. The first is to make public both the technical specification and the Terms of Use of the Instant Personalization program, so that there can be some independent monitoring of bugs and policy violations. The second is to commit resources to ToS enforcement — Facebook needs to signal that their enforcement efforts have some teeth, and that there will be penalties for partners with buggy sites or noncompliant data use practices.
Footnotes.
[1] YCombinator-funded companies will get “priority access” to various Facebook technologies including “Facebook Credits, Instant Personalization and upcoming beta features”. Interestingly, Instant Personalization seems to be the feature that YCombinator is most interested in.
[2] Yelp.com was also found vulnerable to a cross-site scripting bug soon after Instant Personalization launch. This means the majority of partner sites — 3 out of 5 — have had vulnerabilities that compromise Instant Personalization.
[3] In Instant Personalization, Facebook and the partner site communicate invisibly in the background each time the user visits a page on the partner site; in this way the mechanism is different from social widgets.
[4] Large-scale clickstream data is prone to misuse in various ways: government coercion, hacking, or being purchased as part of bankruptcy settlements (expecially when we’re talking about startups).
Thanks to Kevin Bankston for pointing me to Facebook’s log rentention policy for social plugins.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Yet Another Identity Stealing Bug. Will Creeping Normalcy be the Result?
Elie Bursztein points me to a “Cross Site URL Hijacking” attack which, among other things, allows a website to identify a visitor instantly (if they are using Firefox) by finding their Google and possibly Facebook IDs. Here is a live demo and here’s a paper.
For the security geeks, the attack works by exploiting a Firefox bug that allows a page in the attacker domain to infer URLs of pages in the target domain. If a page like target.com/home redirects to target.com/?user=[username] (which is quite common), the attacker can learn the username by requesting the page target.com/home in a script tag.
Let us put this attack in context. Stealing the identity of a web visitor should be familiar to readers of this blog. I’ve recently written about doing this via history stealing, then a bug in Google spreadsheets, and now we have this. While the spreadsheets bug was fixed, the history stealing vulnerability remains in most browsers. Will new bugs be found faster than existing ones getting fixed? The answer is probably yes.
Something that is of much more concern in the long run is Facebook’s instant personalization, which is basically like identity stealing, except it is a feature rather than a bug. Currently Facebook identities are available without user consent to only 3 partners (Yelp, Pandora and docs.com) but there will be inevitable competitive pressures both for Facebook to open this up to more websites as well as for other identity providers to offer a similar service.
Legitimate methods and hacks based on bugs are not entirely distinct. Two XSS attacks on yelp.com were found in quick succession either of which could have been exploited by a third (fourth?) party for identity stealing. Instant personalization (and similar attempts at an “identity layer”) greatly increase the chance of bugs that leak your identity to every website, authorized or not.
As identity-stealing bugs as well as identity-sharing features proliferate, the result is going to be creeping normalcy — users will get slowly inured to the idea that any website they visit might have their identity. And that will be a profound change for the way the web works. Of course, savvy users will know how to turn off the various tracking mechanisms, but most people will be left in the lurch.
We are still at the early stages of this shift. It is clear that it will have both good and ill effects. For example, people are much more civil when interacting under their real-life identity. For this reason, there is quite a clamor for identity. For instance, see News Sites Rethink Anonymous Online Comments and The Forces Align Against Anonymity. But like every change, this one is going to be hard to get used to.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
History Stealing: It’s All Shades of Grey
Previous articles in this series showed that ‘Ubercookies’ can enable websites to learn the identity of any visitor by exploiting the ‘history stealing’ bug in web browsers, and presented different types of de-anonymization attacks. This article is all about the question, “but who is the adversary?”
 Good and evil. It is tempting for security researchers to think of the world in terms of good guys and bad guys — white hats and black hats. It is a view of the world that is probably hardwired into our brains, reflected everywhere from religious beliefs to Hollywood plots. But reality is more complex. Heroes are flawed, and the bad guys are not really evil. But enough with the moral lecture, let’s see how this pertains to history stealing and identity stealing.
Good and evil. It is tempting for security researchers to think of the world in terms of good guys and bad guys — white hats and black hats. It is a view of the world that is probably hardwired into our brains, reflected everywhere from religious beliefs to Hollywood plots. But reality is more complex. Heroes are flawed, and the bad guys are not really evil. But enough with the moral lecture, let’s see how this pertains to history stealing and identity stealing.
Black hat. I don’t need to say very much to convince you of the black-hat uses of learning your identity. I’ve already talked about how a phishing site that knows who you are can deliver a customized page that is dramatically more effective. Or imagine the potential for surveillance — with the cooperation of a single ad network, a Government can put a de-anonymization script on millions of websites and keep tabs on every click anyone makes. In fact, you only need to be de-anonymized once; regular tracking scripts will do the job after that.
Grey hat. But I want to argue here that the grey hat use case is far more likely/common than the black hat. For example, here’s an article arguing that websites should sniff their visitors’ history for a “better user experience.” The nonchalant way in which the author talks about exploiting a nasty bug and the lack of mention of any privacy concerns is both scary and amusing. In the comments section of that article you can find links to implementations. In fact there’s even a website selling history sniffing code that website owners can drop into their site.

Shades of grey. Consider a thought experiment. Suppose a website delivered a “better user experience” by sniffing your history, but didn’t send that information back to the server. Whatever web page customization happens is done purely in the browser using Javascript. Is that unethical? If you think it’s unethical, what about if the site popped up a box to get the user’s consent before doing so? Remember that 80% of users are going to click OK without understanding what the box says. At this point it’s looking pretty close to Adnostic, a paper/project I’ve been working on as a privacy enhancing tool.

My point here is not to defend history stealing. Rather, I hope I’ve convinced you that there’s a gentle gradient between white and black hat, at least in terms of intent, and that it’s hard to condemn someone unequivocally.
Incentive. For the most part, people who are using history sniffing “in the wild” are just trying to make an extra buck on their website through advertising. This is an extremely powerful incentive. You may not know how terrible ad targeting currently is on the web. You can find any number of horror stories like this one from Stack Overflow that says a million pageviews a day aren’t enough to pay one person part time. Anything that improves ad rates directly impacts the bottom line.
Now consider this:
The future of Internet ad targeting may lie in combining online and offline behavioral data. Several Web networks have already formed relationships with, or purchased, offline database companies. AdForce has a relationship with Experion, which has an offline database of about 120 million households in North America; likewise, DoubleClick purchased Abacus Direct, a shared catalog database with information on over 90 million U.S. households. 24/7 Media has also formed an alliance to link online and offline data.
Linking online and offline data means one thing: being able to not only track users online but also identify them. Hundreds of millions of dollars say this is going to happen one way or the other.
Some grey hat use cases. The “improved user experience” article linked above advocates history stealing for picking the right third party service providers to direct the user to by detecting which one they are already using – the right RSS reader, social bookmarking site, federated identity provider, mapping service, etc. But let’s talk about identity stealing instead of just history stealing.
Ad targeting, which I’ve already mentioned, can be improved not just by combining online with offline data but also by combining social network profile data with click tracking data. This may already be happening on some social networking sites, but identity stealing makes it possible to grab the user’s social network profile information no matter which site they’re on.
As I pointed out earlier, users are more likely to fall for phishing when the site addresses them by name. But this effect is not in any way specific to phishing. Any new site that wants to get users to try their service or to stick around longer can benefit from this technique to improve trust. Marketers have long absorbed Dale Carnegie’s wisdom that the sweetest word you can say to a person is their own name.
Grey hat is more worrisome than black hat. There are two reasons to worry about grey hat more than black hat. Every website that doesn’t have a reputation to lose is a potential user of grey hat techniques, whether history stealing or anything else. Second, grey hats are typically not using it for anything illegal (unlike phishers), which means you can’t use the law to shut them down.
This is a general thought that I want to leave computer security researchers. We are used to thinking of adversaries as malicious agents; this thinking has been reinforced by the fact that in the last decade or two, hacking went from harmless pranks to organized crime. But the nature of the adversary who exploits privacy flaws is very different from the case of data security breaches. It is important to keep this distinction in mind to be able to develop effective responses.
The role of the browser. In the next article, I will take a broader look at identity and anonymity on the Web, and discuss the role that browsers are going to play in dictating the default level of identity in the years to come.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Google Docs Identity Leak Bug Fixed
Yesterday I wrote about a bug in Google Docs that lets an arbitrary website find your identity. This morning I woke up to this piece of good news in my Inbox:
The fix is pushed out and live for all users as of the middle of last night. Basically we only show the username of collaborators if they are explicitly listed on the ACL of the spreadsheet. Otherwise we call them “Anonymous user”. This means that an editor of the document had to already know the username in order for that username to be visible to collaborators.
I can confirm that the demo page no longer finds my identity. And the spreadsheet in my last post now looks like this:

The Google Docs help question “Collaborating: Why are some users anonymous?” explains:
If a document is set by the owner to be viewable or editable by everyone, then Google Docs does not show the names of those who choose to view or edit the document. Google Docs displays only the identities of users who are explicitly given permission to view or edit a document (either individually or as part of a group).
You might wonder what happens if the attacker explicitly gives permission to a whole bunch of users (say using scraped email addresses) . There seems to be an extra level of protection now:

Sounds like a happy resolution.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
How Google Docs Leaks Your Identity
Recap. In the previous two articles in this Ubercookies series, I showed how an arbitrary website that you visit can learn your identity using the “history stealing” bug in web browsers. In this article I will show how a bug in Google Docs gives any website the same capability in a far easier manner.
Update. A Google Docs team member tells me that a fix should be live later today.
Update 2. Now fixed.
About six weeks ago I discovered that a feature/bug in Google docs can be used to mass harvest e-mail addresses. I noted it in my journal, but soon afterwards I realized that it was much worse: you could actually discover the identity of web visitors using the bug. Recently, Vincent Toubiana and I implemented the attack; here is a video of the demo webpage (on my domain, in no way related to Google) just to show that we got it working.
(You might need to hit pause to read the text.)
I’m not releasing the live demo, since the vulnerability unfortunately still exists (more on this below). Let us now study the attack in more detail.

Bug or feature? Google Spreadsheets has a feature that tells you who else is editing the document. It’s actually really nifty: you can see in real time who is editing which cell, and it even seems to have live chat. The problem is that this feature is available even for publicly viewable documents. Do you see where this is going?
First of all, this is a problem even without the surreptitious use I’m going to describe. Here’s a public spreadsheet I found with 10 seconds of Googling that a few people seem to be viewing when I looked. I’m not sure the author of this document intended it to be publicly viewable or editable.

The attack works by embedding an invisible iframe (dimensions 0x0) into the malicious web page. The iframe loads a public spreadsheet that the attacker has already created. In a separate backend process, the attacker constantly checks the list of people viewing the spreadsheet and records this information. After the iframe is embedded, the Javascript on the page page waits a second or two and queries the attacker’s server to get the username of the user who most recently appeared on the list.
What if multiple people are visiting the page at roughly the same time? It’s not a problem, for two reasons: 1. Google Spreadsheets has a “push” notification system for updating the frontend which enables the attacker to get the identity of the new user virtually instantaneously. 2. To further increase accuracy, the attacker can create (say) 10 spreadsheets and embed a random subset of 5 into any given visitor’s page, making it exceptionally unlikely that there will be a collision.
The only inefficient part of the attack as Toubiana and I have implemented it is that it requires a browser (with a GUI) to be open to monitor the spreadsheet. Browser rendering engines have been modularized into scriptable components, so with a little more effort it should be possible to run this without a display. At present I have it running out of an old laptop tucked away in my dresser :-)
Defense. How can Google fix this bug? There are stop-gap measures, but as far as I can see the only real solution is to disable the collaborator list for public documents. Again a trade-off between functionality and privacy as we saw in the previous article.
Many people responded to my original post saying they were going to stay logged out of Google when they didn’t need to be logged in (since you can’t log out of just Google Docs separately). Unfortunately, that’s not a feasible solution for me, and I suspect many other people. There are at least 3 Google services that I constantly need to keep tabs on; otherwise my entire workflow would come to a screeching halt. So I just have to wait for Google to do something about this bug. Which brings me to my next point:
Great power, great responsibility. There is a huge commercial benefit to becoming an identity provider. As Michael Arrington has repeatedly noted, many Internet companies issue OpenIDs but don’t accept them from other providers, in a race to “own the identity” of as many users as possible. That is of course business as usual, but the players in this race need to wake up to the fact that being an identity provider is asking users for a great deal of trust, whether or not users realize it.
An identity-stealing bug is an (unintentional) violation of that trust because — among many other reasons — it is a precursor to stealing your actual account credentials. (That is particularly scary with Google due to their lack of anything resembling customer service for account issues.) One strategy for stealing account credentials is a phishing page mimicking the Google login page, with your username filled in. Users are much less likely to be suspicious and more likely to respond to messages that have their name on them. Research on social phishing reaches similar conclusions.
I’ve been in contact with people at Google about this bug and I’ve been told a fix is being worked on, specifically that “less presence information will be revealed.” I take it to mean the attack described here won’t work. Since they are making a good-faith effort to fix it, I’m not releasing the demo itself. It has been a long time, though. The Buzz privacy issues were fixed in 4 days, and that kind of urgency is necessary for security issues of this magnitude.
A kind of request forgery. The attack here can be seen as a simpleminded cross-site request forgery. In general, any type of request forgery bug that causes your browser to initiate a publicly recorded interaction on your behalf will immediately leak you identity. For example, if (hypothetically) visiting a URL causes your browser to leave a comment on a specific Youtube video, then the attacker can create a Youtube video and constantly monitor it for comments, mirroring the attack technique used here.
Another technical lesson from this bug is that access control in social networking can be tricky. I’ve written before that privacy in social networking is about a lot more than access control, and that theory doesn’t help determine user reactions to your product. But this bug was an access control issue, and theory would have helped. Websites designing social features would do well to have someone with an academic background thinking about security issues.
Up next. In this post as well as the previous ones, I’ve briefly hinted at what exactly can go wrong if websites can learn your identity. The next post in this series will examine that issue in more detail. Stay tuned — it turns out there’s quite a bit more to say about that, and you might be surprised.
Thanks to Vincent Toubiana for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Ubercookies Part 2: History Stealing meets the Social Web
Recap. In the previous article I introduced ubercookies — techniques that websites can use to de-anonymize visitors. I discussed a recent paper that shows how to use history stealing along with social network group membership information to find the visitor’s identity, and I promised a stronger variant of the attack.
The observation that led me to the attack I’m going to describe is simple: social networking isn’t just about social networks — the whole web has gone social. It’s a view that you quickly internalize if you spend any time hanging out with Silicon Valley web entrepreneurs :-)
Let’s break the underlying principle of the identity-stealing attack down to its essence:
A user leaves a footprint whenever their interaction with a specific web page is recorded publicly.
De-anonymization happens when the attacker can tie these footprints together into “trails” that can then be correlated with the user’s browser history. Efficiently querying the history to identify multiple points on the trail is a challenging problem to solve, but in principle de-anonymization is possible as long as the user’s actions on different web pages happen under the same identity.
Footprints can be tied together into trails as long as all the interactions happen under the same identity. There is no need for the interactions to be on the same website.
There are two major ways in which you can interact with arbitrary websites under a unified identity, both of which are defining principles of the social web. The first is federated identity, which means you can use the same identity provider wherever you go. This is achieved through OpenID and similar mechanisms like Facebook Connect. The second is social sharing: whenever you find something interesting anywhere on the web, you feed it back to your social network.
Now let’s examine the different types of interactions in more detail.
A taxonomy of interaction on the social web.
0. The pre-social web had no social networks and no delegated identity mechanism (except for the failed attempt by Microsoft called Passport). Users created new identities on each website, authenticated via site-specific usernames and passwords to each site separately. The footprints on different sites cannot be tied together; for practical purposes there are no footprints.

1. Social networks: affiliation. In social networks, users interact with social objects and leave footprints when the actions are public. The key type of interaction that is useful for de-anonymization is the expression of affiliation: this refers to not just the group memberships studied in the recent Wondracek et al. paper, but also includes
- memberships of fan pages on Facebook
- “interests” on Livejournal
- follow relationships and plain old friend relationships on Twitter and other public social networks
- subscriptions to Youtube channels
and so on.
All of these interactions, albeit very different from the user perspective, are fundamentally the same concept:
- you “add yourself” to or affiliate yourself with some object on a social network
- this action can be publicly observed
- you almost certainly visited a URL that identifies the object before adding it.

2. The social web: sharing. When you find a page you like — any page at all — you can import it or “share” it to your social stream, on Facebook, Twitter, Google Buzz, or a social bookmarking site like Delicious. The URL of the page is almost certainly in your history, and as long as your social stream is public, your interaction was recorded publicly.

3. The social web: federated identity. When you’re reading a blog post or article on the social web, you can typically comment on it, “like” it, favorite it, rate it, etc. You do all this under your Facebook, Google or other unified identity. These actions are often public and when they are, your footprint is left on the page.
A taxonomy of attacks
The three types of social interactions above give rise to a neat taxonomy of attacks. They involve progressively easier backend processing and progressively more sophisticated history search techniques on the front end. But the execution time on the front-end doesn’t increase, so it is a net win. Here’s a table:
| Type of interaction |
Backend processing |
Type of history URL |
Location of footprint |
| Affiliation | Crawling of social network | Object in a social network | In the social network |
| Sharing | Syndication of social stream(s) from social network | Any page | In the social network |
| Federated identity | None; optional crawling | Any page | On the page |
.
1. Better use of affiliation information. The Wondracek et al. paper makes use of only group membership. One natural reason to choose groups is that there are many groups that are large, with thousands of members, so it gives us a reasonably high chance that by throwing darts in the browser history we will actually hit a few groups that the user has visited. On the other hand, if we try to use the Facebook friend list, for example, hoping to find one of the user’s friends by random chance, it probably won’t work because most users have only a few hundred friends.
But wait: many Twitter users have thousands or even millions of followers. These are known as “hubs” in network theory. Clearly, the attack will work for any kind of hubs that have predictable URLs, and users on Twitter have even more predictable URLs (twitter.com/username) than groups on various networks. The attack will also work using Youtube favorites (which show up by default on the user’s public profile or channel page) and whatever other types of affiliation we might choose to exploit, as long as there are “hubs” — nodes in the graph with high degree. Already we can see that many more websites are vulnerable than the authors envisaged.
2. Syndicating the social stream: my Delicious experiment.
The interesting thing about the social stream is that you can syndicate the stream of interactions, rather than crawling. The reasons why syndication is much easier than crawling are more practical than theoretical. First, syndicated data is intended to be machine readable, and is therefore smaller as well as easier to parse compared to scraping web pages. Second, and more importantly, you might be to get a feed of the entire site-wide activity instead of syndicating each user’s activity stream separately. Delicious allows global syndication; Twitter plans to open this “firehose” feature to all developers soon.
Another advantage of the social stream is that everything is timestamped, so you can limit yourself to recent interactions, which are more likely to be in the user’s history.
Using the delicious.com dataset made available by DAI-labor (a log of all bookmarking activity on delicious.com over several years), I did a simulated experiment using 3 months worth of data: assuming that users keep their history around for 3 months, do in fact visit every link they post on delicious, how many users would a hypothetical history stealing attack be able to identify? I had a pretty good success rate: about 60% of the users who had shared at least 2 links in the 3-month period, or about 300,000 users. This takes at most 4000-5000 Javascript history queries.
Needless to say, once Twitter opens up its firehose, Twitter users (who are far more numerous than delicious users) would also be susceptible to the same technique.
This attack is not possible to fix via server-side URL randomization. It can also be made to work using Facebook, Google Buzz, and other sharing platforms, although the backend processing required won’t be as trivial (but probably no harder than in the original attack.)
3. A somewhat random walk through the history park.
And now for an approach that potentially requires no backend data collection, although it is speculative and I can’t guess what the success rate would be. The attack proceeds in several steps:
- Identify the user’s interests by testing if they’ve visited various popular topic-specific sites. Pick one of the user’s favorite topics. Incidentally, a commenter on my previous post notes he is building exactly this capability using topic pages on Wikipedia, also with the goal of de-anonymization!
- Grab a list of the top blogs on the topic you picked from one of the blog directories. Query the history to see which of these blogs the user reads frequently. It is even possible to estimate the level of interest in a blogs by looking at the fraction of the top/recent posts from that blog that the user has visited. Pick a blog that the user seems to visit regularly.
- Look for evidence of the user leaving comments on posts. For example, on Blogger, the comment page for a post has the URL http://www.blogger.com/comment.g?blogID=<blogid>&postID=<postid>.
- Once you find a couple of posts where it looks like the user made a comment, scrape the list of people who commented on it, find the intersection. (Even a single comment might suffice; as long as you have a list of candidates, you easily verify if it’s one of them by testing user-specific URLs. More below.)
- Depending on the blogging platform, you might even be able to deduce that the user responded (or intended to respond) to a specific comment. For example, On wordpress you have the pattern http://<blogname>.wordpress.com/<postname>/?replytocom=<commentid>#respond. If you get lucky and find one of those patterns, that makes things even easier.
If at first you don’t succeed, pick a different blog and repeat.
I suspect that the most practical method would be to use a syndicated activity stream from a social network, but also to use the heuristics presented above to more efficiently search through the history.
Epilogue: Identity.
Not only has there been a movement towards a small number of identity providers on the web, there are many aggregators out there that have sprung up in order to automatically find the connections between identities across the different identity providers, and also connect online identities to physical-world databases. As Pete Warden notes:
One of the least-understood developments of the last few years is the growth of databases of personal information linked to email addresses. Rapleaf is probably the leader in this field, but even Flickr lets companies search their API for users based on an email address.
I ran my email address through his demo script and it is quite clear that virtually all of my online identities have been linked together. This is getting to be the norm; as a consequence, once an attacker gets any kind of handle on you, they can go “identity hopping” and find out a whole lot more about you.
This is also the reason that once the attacker can make a reasonable guess at the visitor’s identity, it’s easy to verify the guess. Not only can they look for user-specific URLs in your history to confirm the guess (described in detail in the Wondracek et al. paper), but all your social streams on other sites can also be combined with your history to corroborate your identity.
Up next in the Ubercookies series: So that’s pretty bad. But it’s going to get worse before it can get better :-) In the next article, I will describe an entirely different attack strategy to get at your identity by exploiting a bug in a specific identity provider’s platform.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Cookies, Supercookies and Ubercookies: Stealing the Identity of Web Visitors
 Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Cookies. Most people are aware that their web browsing activity over time and across sites can be tracked using cookies. When you are being tracked, it can be deduced that the same person visited certain sites at certain times, but the sites doing the tracking don’t know who you are, i.e., you name, etc., unless you choose to tell them in some way, such as by logging in.
Cookies are easy to delete, and so there’s been a big impetus in the Internet advertising industry to discover and deploy more robust tracking mechanisms.
Supercookies. You may surprised to find just how helpless a user is against a site (or more usually, a network of sites) that is truly determined to track them. There are Flash cookies, much harder to delete, some of which respawn the regular HTTP cookies that you delete. The EFF’s Panopticlick project demonstrates many “browser fingerprinting” methods which are more sophisticated. (Jonathan Mayer’s senior thesis contained a smaller-scale demonstration of some of those techniques).
A major underlying reason for a lot of these problems is that any browser feature that allows a website to store “state” on the client can be abused for tracking, and there are a bewildering variety of these. There is a great analysis in a paper by my Stanford colleagues. One of the points they make is that co-operative tracking by websites is essentially impossible to defend against.
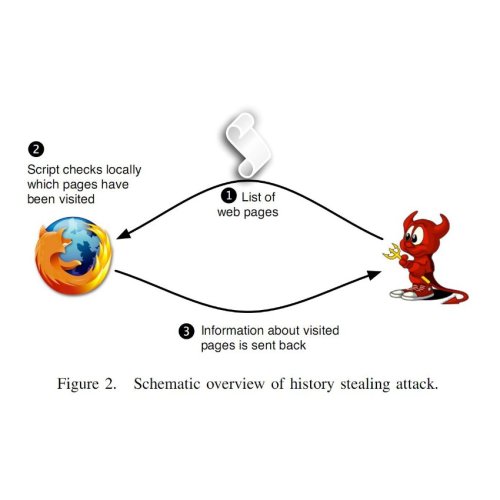
Ubercookies: history stealing. Now let’s get to the scary stuff: uncovering identity. History stealing or history sniffing is an unintended consequence of the way the web is designed; it allows a website to learn which URLs you’ve been to. While a site can’t simply ask your browser for a list of visited URLs, it can ask “yes/no” questions and your browser will faithfully respond. The most common way of doing this is by injecting invisible links into the page using Javascript and exploiting the fact that the CSS link color attribute depends on whether the link has been visited or not.
History stealing has been known for a decade, and browser vendors have failed to fix it because it cannot be fixed without sacrificing some useful functionality (the crude way is to turn off visited link coloring altogether; a subtler solution is SafeHistory). Increasingly worse consequences have been discovered over the years: for example, a malicious site can learn which bank you use and customize a phishing page accordingly. But a paper (full text, PDF) coming out at this year’s IEEE S&P conference at Oakland takes it to a new level.
Identity. Let’s pause for a second and think about what finding your identity means. In the modern, social web, social network accounts have become our de-facto online identities, and most people reveal their name and at least some other real-world information about ourselves on our profiles. So if the attacker can discover the URL of your social network profile, we can agree that he has identified you for all practical purposes. And the new paper shows how to do just that.
The attack relies on the following observations:
- Almost all social networking sites have some kind of “group” functionality: users can add themselves to groups.
- Users typically add themselves to multiple groups, at least some of which are public.
- Group affiliations, just like your movie-watching history and many other types of attributes, are sufficient to fingerprint a user. There’s a high chance there’s no one else who belongs to the same set of groups that you do (or is even close). [Aside: I used this fact to show that Lending Club data can be de-anonymized.]
- Users who belong to a group are likely to visit group-specific URLs that are predictable.
Put the above facts together, and the attack emerges: the attacker (an arbitrary website you visit, without the co-operation of whichever social network is used as an attack enabler) uses history stealing to test a bunch of group-related URLs one by one until he finds a few (public) groups that the anonymous user probably belongs to. The attacker has already crawled the social network, and therefore knows which user belongs to which groups. Now he puts two and two together: using the list of groups he got from the browser, he does a search on the backend to find the (usually unique) user who belongs to all those groups.
Needless to say, this is a somewhat simplified description. The algorithm can be easily modified so that it will work even if some of the groups have disappeared from your history (say because you clear it once in a while) or if you’ve visited groups you’re not a member of. The authors demonstrated that the attack with real users on the Xing network, and also showed theoretically that it is feasible on a number of other social networks including Facebook and Myspace. It takes a few thousand Javascript queries and runs in a few seconds on modern browsers, which makes it pretty much surreptitious.
Fallout. There are only two ways to try to fix this. The first is for all the social networking sites to change their URL patterns by randomizing them so that point 4 above (predictable URL identifying that you belong to a group) is no longer true. The second is for all the browser vendors to fix their browsers so that history stealing is no longer possible.
The authors contacted several of the social networks; Xing quickly implemented the URL randomization fix, which I find surprising and impressive. Ultimately, however, Xing’s move will probably be no more than a nice gesture, for the following reason.
Over the last few days, I have been working on a stronger version of this attack which:
- can make use of every URL in the browser history to try and identify the user. This means that server-side fixes are not possible, because literally every site on the web would need to implement randomization.
- avoids the costly crawling step, further lowering the bar to executing the attack.
That leaves browser-based fixes for history stealing, which hasn’t happened in the 10 years that the problem has been known. Will browsers vendors finally accept the functionality hit and deal with the problem? We can hope so, but it remains to be seen.
In the next article, I will describe the stronger attack and also explain in more detail why your profile page on almost any website is a very strong identifier.
Thanks to Adam Bossy for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.


{kind=link}