Posts tagged ‘do not track’
Tracking Not Required: Behavioral Targeting
Co-authored by Jonathan Mayer and Subodh Iyengar.
In the first installment of the Tracking Not Required series, we discussed a relatively straightforward case: frequency capping. Now let’s get to the 800-pound gorilla, behaviorally targeted advertising, putatively the main driver of online tracking. We will show how to swap a little functionality for a lot of privacy.
Admittedly, implementing behavioral targeting on the client is hard and will require some technical wizardry. It doesn’t come for “free” in that it requires a trade-off in terms of various privacy and deployability desiderata. Fortunately, this has been a fertile topic of research over the past several years, and there are papers describing solutions at a variety of points on the privacy-deployability spectrum. This post will survey these papers, and propose a simplification of the Adnostic approach — along with prototype code — that offers significant privacy and is straightforward to implement.
Goals. Carrying out behavioral advertising without tracking requires several things. First, the user needs to be profiled and categorized based on their browsing history. In nearly all proposed solutions, this happens in the user’s browser. Second, we need an algorithm for selecting targeted ads to display each time the user visits a page. If the profile is stored locally and not shared with the advertising company, this is quite nontrivial. The final component is for reporting of ad impressions and clicks. This component must also deal with click fraud, impression fraud and other threats.
Existing approaches
The chart presents an overview of existing and proposed architectures.
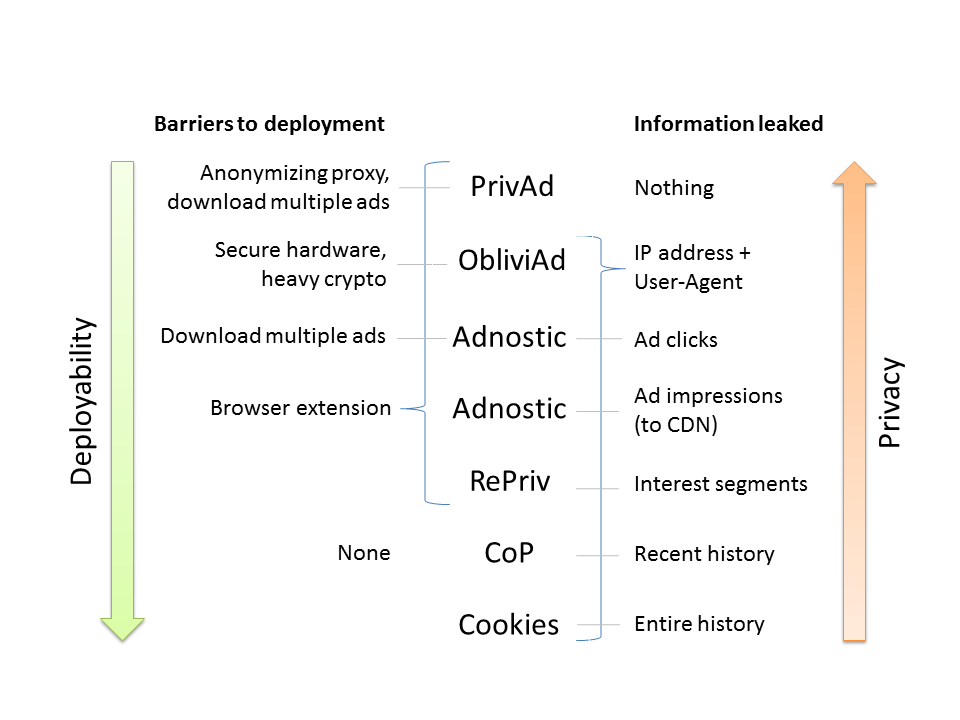
“Cookies” refers to the status quo of server-side tracking; all other architectures are presented in research papers summarized in the Do Not Track bibliography page. CoP stands for “Client-only Profiles,” the architecture proposed by Bilenko and Richardson.
Several points of note. First, everything except PrivAd — which uses an anonymizing proxy — reveals the IP address, and typically the User Agent and Referer to the ad company as part of normal HTTP requests. Second, everything except CoP (and the status quo of tracking cookies) requires software installation. Opinions vary on just how much of a barrier this is. Third, we don’t take a stance on whether PrivAd is more deployable than ObliviAd or vice-versa; they both face significant hurdles. Finally, Adnostic can be used in one of two modes, hence it is listed twice.
There is an interesting technological approach, not listed above, that works by exposing more limited referer information. Without the referer header (or an equivalent), the ad server may identify the user but will not learn the first-party URL, and thus will not be able to track. This will be explored in more depth in a future article.
New approach. In the solution we propose here, the server is recruited for profiling, but doesn’t store the profile. This avoids the need for software installation and allows easy deployability. In addition, non-tracking is externally verifiable, to the extent that IP address + User-Agent is not nearly as effective for tracking as cookie-based unique identifiers.[1] Like CoP, and unlike Adnostic, each ad company can only profile users during visits to pages that it has a third-party presence on, rather than all pages.
Profiling algorithm.
1. The user visits a page that has embedded content from the ad company.
2. JavaScript in the ad company’s content sends the top-level URL to a special classifier service run by the ad company. (The classifier is run on a separate domain. It does not have any cookies or other information specific to the user.)
3. The classifier returns a topic classification of the page.
4. The ad company’s JavaScript receives the page classification and uses it to update the user’s behavioral profile in HTML5 storage. The JavaScript may also consider other factors, such as how long the user stayed on the page.
There is a fair degree of flexibility in steps 3 and 4 — essentially any profiling algorithm can be implemented by appropriately splitting it into a server-side component that classifies individual web pages and a client-side component that analyzes the user’s interaction with these pages.
Ad serving and accounting.
The ad serving process in our proposal is the same as in Adnostic — the server sends a list of ads along with metadata describing each ad, and the client-side component picks the ad that best matches the locally stored profile. To avoid revealing which ad was displayed, the client can either download all (say, 10) ads in the list while displaying only one, or the client downloads only one ad, but ads are served from a different domain which does not share cookies with the tracking domain. Note the similarity to our frequency capping approach, both in terms of the algorithm and its privacy properties.
Accounting, i.e., billing the right advertiser is also identical to Adnostic for the cost-per-click and cost-per-impression models; we refer the reader there. Discussing the cost-per-action model is deferred to a future post.
Implementation. We implemented our behavioral targeting algorithm using HTML 5 local storage. As with our frequency capping implementation, we found performance was exceptionally fast in modern desktop and mobile browsers. For simplicity, our implementation uses a static local database mapping websites to interest segments and a binary threshold for determining interests. In practice, we expect implementers would maintain the mapping server-side and apply more sophisticated logic client-side.
We also present a different work-in-progress implementation that’s broader in scope, encompassing retargeting, behavioral targeting and frequency capping.
Conclusion. Certainly there are costs to our approach — a “thick-client” model will always be slightly more inconvenient to deploy and maintain than a server-based model, and will probably have a lower targeting accuracy. However, we view these costs as minimal compared to the benefits. Some compromise is necessary to get past the current stalemate in web tracking.
Technological feasibility is necessary, but not sufficient, to change the status quo in online tracking. The other key component is incentives. That is why Do Not Track, standards and advocacy are crucial to the online privacy equation.
[1] The engineering and business reasons for this difference in effectiveness will be discussed in a future post.
To stay on top of future posts, subscribe to the RSS feed or follow me on Google+.
Privacy and the Market for Lemons, or How Websites Are Like Used Cars
I had a fun and engaging discussion on the “Paying With Data” panel at the South by Southwest conference; many thanks to my co-panelists Sara Marie Watson, Julia Angwin and Sam Yagan. I’d like to elaborate here on a concept that I briefly touched upon during the panel.
The market for lemons
 In a groundbreaking paper 40 years ago, economist George Akerlof explained why so many used cars are lemons. The key is “asymmetric information:” the seller of a car knows more about its condition than the buyer does. This leads to “adverse selection” and a negative feedback spiral, with buyers tending to assume that there are hidden problems with cars on the market, which brings down prices and disincentivizes owners of good cars from trying to sell, further reinforcing the perception of bad quality.
In a groundbreaking paper 40 years ago, economist George Akerlof explained why so many used cars are lemons. The key is “asymmetric information:” the seller of a car knows more about its condition than the buyer does. This leads to “adverse selection” and a negative feedback spiral, with buyers tending to assume that there are hidden problems with cars on the market, which brings down prices and disincentivizes owners of good cars from trying to sell, further reinforcing the perception of bad quality.
In general, a market with asymmetric information is in danger of developing these characteristics: 1. buyers/consumers lack the ability to distinguish between high and low quality products 2. sellers/service providers lose the incentive to focus on quality and 3. the bad gradually crowds out the good since poor-quality products are cheaper to produce.
Information security and privacy suffer from this problem at least as much as used cars do.
The market for security products and certification
 Bruce Schneier describes how various security products, such as USB drives, have turned into a lemon market. And in a fascinating paper, Ben Edelman analyzes data from TRUSTe certifications and comes to some startling conclusions [emphasis mine]:
Bruce Schneier describes how various security products, such as USB drives, have turned into a lemon market. And in a fascinating paper, Ben Edelman analyzes data from TRUSTe certifications and comes to some startling conclusions [emphasis mine]:
Widely-used online “trust” authorities issue certifications without substantial verification of recipients’ actual trustworthiness. This lax approach gives rise to adverse selection: The sites that seek and obtain trust certifications are actually less trustworthy than others. Using a new dataset on web site safety, I demonstrate that sites certified by the best-known authority, TRUSTe, are more than twice as likely to be untrustworthy as uncertified sites. This difference remains statistically and economically significant when restricted to “complex” commercial sites.
[…]
In a 2004 investigation after user complaints, TRUSTe gave Gratis Internet a clean bill of health. Yet subsequent New York Attorney General litigation uncovered Gratis’ exceptionally far-reaching privacy policy violations — selling 7.2 million users’ names, email addresses, street addresses, and phone numbers, despite a privacy policy exactly to the contrary.[…]
TRUSTe’s “Watchdog Reports” also indicate a lack of focus on enforcement. TRUSTe’s postings reveal that users continue to submit hundreds of complaints each month. But of the 3,416 complaints received since January 2003, TRUSTe concluded that not a single one required any change to any member’s operations, privacy statement, or privacy practices, nor did any complaint require any revocation or on-site audit. Other aspects of TRUSTe’s watchdog system also indicate a lack of diligence.
The market for personal data
 In the realm of online privacy and data collection, the information asymmetry results from a serious lack of transparency around privacy policies. The website or service provider knows what happens to data that’s collected, but the user generally doesn’t. This arises due to several economic, architectural, cognitive and regulatory limitations/flaws:
In the realm of online privacy and data collection, the information asymmetry results from a serious lack of transparency around privacy policies. The website or service provider knows what happens to data that’s collected, but the user generally doesn’t. This arises due to several economic, architectural, cognitive and regulatory limitations/flaws:
- Each click is a transaction. As a user browses around the web, she interacts with dozens of websites and performs hundreds of actions per day. It is impossible to make privacy decisions with every click, or have a meaningful business relationship with each website, and hold them accountable for their data collection practices.
- Technology is hard to understand. Companies can often get away with meaningless privacy guarantees such as “anonymization” as a magic bullet, or “military-grade security,” a nonsensical term. The complexity of private browsing mode has led to user confusion and a false sense of safety.
- Privacy policies are filled with legalese and no one reads them, which means that disclosures made therein count for nothing. Yet, courts have upheld them as enforceable, disincentivizing websites from finding ways to communicate more clearly.
Collectively, these flaws have led to a well-documented market failure—there’s an arms race to use all means possible to entice users to give up more information, as well as to collect it passively through ever-more intrusive means. Self-regulatory organizations become captured by those they are supposed to regulate, and therefore their effectiveness quickly evaporates.
TRUSTe seems to be up to some shenanigans the online tracking space as well. As many have pointed out, the TRUSTe “Tracking Protection List” for Internet Explorer is in fact a whitelist, allowing about 4,000 domains—almost certainly from companies that have paid TRUSTe—to track the user. Worse, installing the TRUSTe list seems to override the blocking of a domain via another list!
Possible solutions
The obvious response to a market with asymmetric information is to correct the information asymmetry—for used cars, it involves taking it to a mechanic, and for online privacy, it is consumer education. Indeed, the What They Know series has done just that, and has been a big reason why we’re having this conversation today.
However, I am skeptical that the market can be fixed though consumer awareness alone. Many of the factors I’ve laid out above involve fundamental cognitive limitations, and while consumers may be well-educated about the general dangers prevalent online, it does not necessarily help them make fine-grained decisions.
It is for these reasons that some sort of Government regulation of the online data-gathering ecosystem seems necessary. Regulatory capture is of course still a threat, but less so than with self-regulation. Jonathan Mayer and I point out in our FTC Comment that ad industry self-regulation of online tracking has been a failure, and argue that the FTC must step in and enforce Do Not Track.
In summary, information asymmetry occurs in many markets related to security and privacy, leading in most cases to a spiraling decline in quality of products and services from a consumer perspective. Before we can talk about solutions, we must clearly understand why the market won’t fix itself, and in this post I have shown why that’s the case.
Update. TRUSTe president Fran Maier responds in the comments.
Update 2. Chris Soghoian points me to this paper analyzing privacy economics as a lemon market, which seems highly relevant.
Thanks to Jonathan Mayer for helpful feedback.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
“Do Not Track” Explained
While the debate over online behavioral advertising and tracking has been going on for several years, it has recently intensified due to media coverage — for example, the Wall Street Journal What They Know series — and congressional and senate attention. The problems are clear; what can be done? Since purely technological solutions don’t seem to exist, it is time to consider legislative remedies.
One of the simplest and potentially most effective proposals is Do Not Track (DNT) which would give users a way to opt out of behavioral tracking universally. It is a way to move past the arms race between tracking technologies and defense mechanisms, focusing on the actions of the trackers rather than their tools. A variety of consumer groups and civil liberties organizations have expressed support for Do Not Track; Jon Leibowitz, chairman of the Federal Trade Comission has also indicated that DNT is on the agency’s radar.
Not a list. While Do Not Track is named in analogy to the Do Not Call registry, and the two are similar in spirit, they are very different in implementation. Early DNT proposals envisaged a registry of users, or a registry of tracking domains; both are needlessly complicated.
The user-registry approach has various shortcomings, at least one of which is fatal: there are no universally recognized user identifiers in use on the Web. Tracking is based on ad-hoc identification mechanisms, including cookies, that the ad networks deploy; by mandating a global, robust identifer, a user registry would in one sense exacerbate the very problem it attempts to solve. It also allows for little flexibility in allowing the user to configure DNT on a site-by-site basis.
The domain-registry approach involves mandating ad networks to register domains used for tracking with a central authority. Users would have the ability to download this list of domains and configure their browser to block them. This strategy has multiple problems, including: (i) the centralization required makes it fickle (ii) it is not clear how to block tracking domains without blocking ads altogether, since displaying an ad requires contacting the server that hosts it and (iii) it requires a level of consumer vigilance that is unreasonable to expect — for example, making sure that the domain list is kept up-to-date by every piece of installed web-enabled software.
The header approach. Today, consensus has been emerging around a far simpler DNT mechanism: have the browser signal to websites the user’s wish to opt out of tracking, specifially, via a HTTP header, such as “X-Do-Not-Track”. The header is sent out with every web request — this includes the page the user wishes to view, as well as each of the objects and scripts embedded within the page, including ads and trackers. It is trivial to implement in the web browser — indeed, there is already a Firefox add-on that implements a such a header.
The header-based approach also has the advantage of requiring no centralization or persistence. But in order for it to be meaningful, advertisers will have to respect the user’s preference not to be tracked. How would this be enforced? There is a spectrum of possibilities, ranging from self-regulation via the Network Advertising Initiative, to supervised self-regulation or “co-regulation,” to direct regulation.
At the very least, by standardizing the mechanism and meaning of opt-out, the DNT header promises a greatly simplified way for users to opt-out compared to the current cookie mechanism. Opt-out cookies are not robust, they are not supported by all ad networks, and are interpreted variously by those that do (no tracking vs. no behavioral advertising). The DNT header avoids these limitations and is also future-proof, in that a newly emergent ad network requires no new user action.
In the rest of this article, I will discuss the technical aspects of the header-based Do Not Track proposal. I will discuss four issues: the danger of a tiered web, how to define tracking, detecting violations, and finally user-empowerment tools. Throughout this discussion I will make a conceptual distinction between content providers or publishers (2nd party) and ad networks (3rd party).
Tiered web. Harlan Yu has raised a concern that DNT will lead to a tiered web in which sites will require users to disable DNT to access certain features or content. This type of restriction, if widespread, could substantially undermine the effectiveness of DNT.
There are two questions to address here: how likely is it that DNT will lead to a tiered web, and what, if anything, should be done to prevent it. The latter is a policy question — should DNT regulation prevent sites from tiering service — so I will restrict myself to the former.
Examining ad blocking allows us to predict how publishers, whether acting by themselves or due to pressure from advertisers, might react to DNT. From the user’s perspective, assuming DNT is implemented as a browser plug-in, ad blocking and DNT would be equivalent to install and, as necessary, disable for certain sites. And from the site’s perspective, ad blocking would result in a far greater decline in revenue than merely preventing behavioral ads. We should therefore expect that DNT will be at least as well tolerated by websites as ad blocking.
This is encouraging, since there are very few mainstream sites today that refuse to serve content to visitors with ad blocking enabled. Ad blocking is quite popular (indeed, the most popular extensions for both Firefox and Chrome are ad blockers). A few sites have experimented with tiering for ad-blocking users, but soon after rescinded due to user backlash. Public perception is a another factor that is likely to skew things even further in favor of DNT being well-tolerated: access to content in exchange for watching ads sounds like a much more palatable bargain than access in exchange for giving up privacy.
One might nonetheless speculate what a tiered web might look like if the ad industry, for whatever reason, decided to take a hard stance against DNT. It is once again easy to look to existing technologies, since we already have a tiered web: logged-in vs anonymous browsing. To reiterate, I do not believe that disabling DNT as a requirement for service will become anywhere near as prevalent as logging in as a requirement for service. I bring up login only to make the comforting observation there seems to be a healthy equilibrium between sites that require login always, some of the time, or never.
Defining tracking. It is beyond the scope of this article to give a complete definition of tracking. Any viable definition will necessarily be complex and comprise both technological and policy components. Eliminating loopholes and at the same time avoiding collateral damage — for example, to web analytics or click-fraud detection — will be a tricky proposition. What I will do instead is bring up a list of questions that will need to be addressed by any such definition:
- How are 2nd parties and 3rd parties delineated? Does DNT affect 2nd-party data collection in any manner, or only 3rd parties?
- Are only specific uses of tracking (primarily, targeted advertising) covered, or is all cross-site tracking covered by default, save possibly for specific exceptions?
- Under use-cases covered (i.e., prohibited) under DNT, can 3rd parties collect any individual data at all or should no data be collected? What about aggregate statistical data?
- If individual data can be collected, what categories? How long can it be retained, and for what purposes can it be used?
Detecting violations. The majority of ad networks will likely have an incentive to comply voluntarily with DNT. Nonetheless, it would be useful to build technological tools to detect tracking or behavioral advertising carried out in violation of DNT. It is important to note that since some types of tracking might be permitted by DNT, the tools in question are merely aids to determine when a further investigation is warranted.
There are a variety of passive (“fingerprinting”) and active (“tagging”) techniques to track users. Tagging is trivially detectable, since it requires modifying the state of the browser. As for fingerprinting, everything except for IP address and the user-agent string requires extra API calls and network activity that is in principle detectable. In summary, some crude tracking methods might be able to pass under the radar, while the finer grained and more reliable methods are detectable.
Detection of impermissible behavioral advertising is significantly easier. Intuitively, two users with DNT enabled should see roughly the same distribution of advertisements on the same web page, no matter how different their browsing history. In a single page view, there could be differences due to fluctuating inventories, A/B testing, and randomness, but in the aggregate, two DNT users should see the same ads. The challenge would be in automating as much of this testing process as possible.
User empowerment technologies. As noted earlier, there is already a Firefox add-on that implements a DNT HTTP header. It should be fairly straightforward to create one for each of the other major browsers. If for some reason this were not possible for a specific browser, an HTTP proxy (for instance, based on privoxy) is another viable solution, and it is independent of the browser.
A useful feature for the add-ons would be the ability to enable/disable DNT on a site-by-site basis. This capability could be very powerful, with the caveat that the user-interface needs to be carefully designed to avoid usability problems. The user could choose to allow all trackers on a given 2nd party domain, or allow tracking by a specific 3rd party on all domains, or some combination of these. One might even imagine lists of block/allow rules similar to the Adblock Plus filter lists, reflecting commonly held perceptions of trust.
To prevent fingerprinting, web browsers should attempt to minimize the amount of information leaked by web requests and APIs. There are 3 contexts in which this could be implemented: by default, as part of the existing private browsing mode, or in a new “anonymous browsing mode.” While minimizing information leakage benefits all users, it helps DNT users in particular by making it harder to implement silent tracking mechanisms. Both Mozilla and reportedly the Chrome team are already making serious efforts in this direction, and I would encourage other browser vendors to do the same.
A final avenue for user empowerment that I want to highlight is the possibility of achieving some form of browser history-based targeting without tracking. This gives me an opportunity to plug Adnostic, a Stanford-NYU collaborative effort which was developed with just this motivation. Our whitepaper describes the design as well as a prototype implementation.

This article is the result of several conversations with Jonathan Mayer and Lee Tien, as well as discussions with Peter Eckersley, Sid Stamm, John Mitchell, Dan Boneh and others. Elie Bursztein also deserves thanks for originally bringing DNT to my attention. Any errors, omissions and opinions are my own.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.

