Cookies, Supercookies and Ubercookies: Stealing the Identity of Web Visitors
February 18, 2010 at 7:49 am 28 comments
 Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Synopsis. Highly sticky techniques called supercookies for tracking web visitors are becoming well known. But the state of the art has in fact advanced beyond tracking, allowing a website to learn the identity of a visitor. I will call these techniques ubercookies; this article describes one such recently discovered technique. Future articles in this series will describe even more powerful variants and discuss the implications.
Cookies. Most people are aware that their web browsing activity over time and across sites can be tracked using cookies. When you are being tracked, it can be deduced that the same person visited certain sites at certain times, but the sites doing the tracking don’t know who you are, i.e., you name, etc., unless you choose to tell them in some way, such as by logging in.
Cookies are easy to delete, and so there’s been a big impetus in the Internet advertising industry to discover and deploy more robust tracking mechanisms.
Supercookies. You may surprised to find just how helpless a user is against a site (or more usually, a network of sites) that is truly determined to track them. There are Flash cookies, much harder to delete, some of which respawn the regular HTTP cookies that you delete. The EFF’s Panopticlick project demonstrates many “browser fingerprinting” methods which are more sophisticated. (Jonathan Mayer’s senior thesis contained a smaller-scale demonstration of some of those techniques).
A major underlying reason for a lot of these problems is that any browser feature that allows a website to store “state” on the client can be abused for tracking, and there are a bewildering variety of these. There is a great analysis in a paper by my Stanford colleagues. One of the points they make is that co-operative tracking by websites is essentially impossible to defend against.
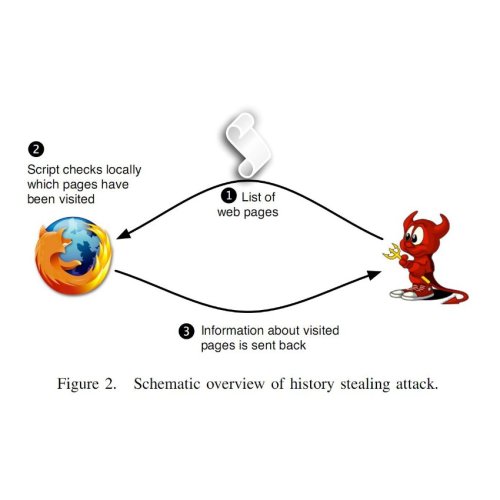
Ubercookies: history stealing. Now let’s get to the scary stuff: uncovering identity. History stealing or history sniffing is an unintended consequence of the way the web is designed; it allows a website to learn which URLs you’ve been to. While a site can’t simply ask your browser for a list of visited URLs, it can ask “yes/no” questions and your browser will faithfully respond. The most common way of doing this is by injecting invisible links into the page using Javascript and exploiting the fact that the CSS link color attribute depends on whether the link has been visited or not.
History stealing has been known for a decade, and browser vendors have failed to fix it because it cannot be fixed without sacrificing some useful functionality (the crude way is to turn off visited link coloring altogether; a subtler solution is SafeHistory). Increasingly worse consequences have been discovered over the years: for example, a malicious site can learn which bank you use and customize a phishing page accordingly. But a paper (full text, PDF) coming out at this year’s IEEE S&P conference at Oakland takes it to a new level.
Identity. Let’s pause for a second and think about what finding your identity means. In the modern, social web, social network accounts have become our de-facto online identities, and most people reveal their name and at least some other real-world information about ourselves on our profiles. So if the attacker can discover the URL of your social network profile, we can agree that he has identified you for all practical purposes. And the new paper shows how to do just that.
The attack relies on the following observations:
- Almost all social networking sites have some kind of “group” functionality: users can add themselves to groups.
- Users typically add themselves to multiple groups, at least some of which are public.
- Group affiliations, just like your movie-watching history and many other types of attributes, are sufficient to fingerprint a user. There’s a high chance there’s no one else who belongs to the same set of groups that you do (or is even close). [Aside: I used this fact to show that Lending Club data can be de-anonymized.]
- Users who belong to a group are likely to visit group-specific URLs that are predictable.
Put the above facts together, and the attack emerges: the attacker (an arbitrary website you visit, without the co-operation of whichever social network is used as an attack enabler) uses history stealing to test a bunch of group-related URLs one by one until he finds a few (public) groups that the anonymous user probably belongs to. The attacker has already crawled the social network, and therefore knows which user belongs to which groups. Now he puts two and two together: using the list of groups he got from the browser, he does a search on the backend to find the (usually unique) user who belongs to all those groups.
Needless to say, this is a somewhat simplified description. The algorithm can be easily modified so that it will work even if some of the groups have disappeared from your history (say because you clear it once in a while) or if you’ve visited groups you’re not a member of. The authors demonstrated that the attack with real users on the Xing network, and also showed theoretically that it is feasible on a number of other social networks including Facebook and Myspace. It takes a few thousand Javascript queries and runs in a few seconds on modern browsers, which makes it pretty much surreptitious.
Fallout. There are only two ways to try to fix this. The first is for all the social networking sites to change their URL patterns by randomizing them so that point 4 above (predictable URL identifying that you belong to a group) is no longer true. The second is for all the browser vendors to fix their browsers so that history stealing is no longer possible.
The authors contacted several of the social networks; Xing quickly implemented the URL randomization fix, which I find surprising and impressive. Ultimately, however, Xing’s move will probably be no more than a nice gesture, for the following reason.
Over the last few days, I have been working on a stronger version of this attack which:
- can make use of every URL in the browser history to try and identify the user. This means that server-side fixes are not possible, because literally every site on the web would need to implement randomization.
- avoids the costly crawling step, further lowering the bar to executing the attack.
That leaves browser-based fixes for history stealing, which hasn’t happened in the 10 years that the problem has been known. Will browsers vendors finally accept the functionality hit and deal with the problem? We can hope so, but it remains to be seen.
In the next article, I will describe the stronger attack and also explain in more detail why your profile page on almost any website is a very strong identifier.
Thanks to Adam Bossy for reviewing a draft.
To stay on top of future posts, subscribe to the RSS feed or follow me on Twitter.
Entry filed under: Uncategorized. Tags: anonymity, cookies, de-anonymization, history stealing, social networks, supercookies, ubercookies, web browsers.
28 Comments Add your own
Leave a reply to Jeremy Moskowitz Cancel reply
Trackback this post | Subscribe to the comments via RSS Feed


{kind=link}
1. yungchin | February 18, 2010 at 4:18 pm
yungchin | February 18, 2010 at 4:18 pm
> In the next article, I will describe the stronger attack …
This is the cliffhanger of the year. Can’t wait!
2. Tiago S. | February 18, 2010 at 6:28 pm
Tiago S. | February 18, 2010 at 6:28 pm
Thanks for the article. I’m looking forward your next post.
3. Andrew | February 18, 2010 at 8:44 pm
Andrew | February 18, 2010 at 8:44 pm
Interesting, I’ve been working on a similiar project to search through a user’s wikipedia browsing history (with the aim of using that information to identify a user’s interests then facebook groups then identity). I’ve setup a proof of concept here (warning, if you follow this link, your wikipedia browsing history will be searched).
4. Arvind | February 18, 2010 at 8:50 pm
Arvind | February 18, 2010 at 8:50 pm
That is fascinating! I was going to hint at similar techniques in my next post. I suggest you put a warning on the page itself, and request the user click a button before you fire off your JS.
5. Gracie | February 18, 2010 at 11:30 pm
Gracie | February 18, 2010 at 11:30 pm
Andrew, do you have a website I can go to in order to contact you (or an email address)?
6. Viktor | February 19, 2010 at 12:04 am
Viktor | February 19, 2010 at 12:04 am
I didn’t realize the extent of the seriousness of history hacks. I guess it’s because I don’t save history.
I think browsers should just forget about the :visited css attribute altogether. It’s so pointless that most websites specifically make sure visited links appear the same colour as non-visited.
7. Arvind | February 19, 2010 at 1:13 am
Arvind | February 19, 2010 at 1:13 am
Here are two use cases for visited link coloring:
1. Searches. When I’ve explored a few search results and then go back to the results page, it would be highly inconvenient not to be able to see at a glance which links I’ve already looked at.
2. News. I get my tech news from Hacker News. Given the high density of links on the page, without being able to differentiate stories I’ve read from ones I haven’t, the site would be nearly unusable for me.
Turning off :visited by fiat is not really an option. You should look at SafeHistory, which I pointed to in the article. It disables history stealing while preserving the above use cases (although I can come up with other much rarer use cases that it doesn’t preserve.)
8. anonymous | February 21, 2010 at 2:34 am
anonymous | February 21, 2010 at 2:34 am
GAAAH Mozilla has disabled the whole ‘visited’ pseudoclass completely in porn mode. It is “highly inconvenient not to be able to see at a glance which (porn) I’ve already looked at.” :D :P
@arvind: what use cases does safe-history not preserve?
9. Arvind | February 21, 2010 at 2:42 am
Arvind | February 21, 2010 at 2:42 am
Re. porn mode: Are you sure that’s what is happening? I would have thought it’s just that non private mode history is not available in private mode (and of course, vice versa).
Re. SafeHistory. Originally I was thinking of this: 1. do a search on Google 2. check out a bunch of results, don’t find what you want 3. give up and do the same search on Bing 4. can’t see which results you’ve already visited because of SafeHistory.
Someone else pointed out that this also breaks news: since the same stories are being shared on different social news sites (often with different headlines), if you use multiple sites to consume news you can’t see which stories you’ve already read.
10. anonymous | February 21, 2010 at 4:30 am
anonymous | February 21, 2010 at 4:30 am
ofcourse I am sure. I don’t joke about my porn! :)
jokes apart : I tried multiple things : opened up private browsing , went to google , clicked on a result then went back and everything was blue. Open a couple of famous sites (google, yahoo,bing) and went to startpanic.com and it only detected startpanic.com
I am sure that is the behavior.
regarding safe-history : I don’t know what the firefox extension does, but I am thinking of this based on the CSP strawman proposal that Collin wrote [1]. Why can’t a browser disable the pseudoclass for visited links, but still change colors of visited links to a default (say the usual pink) ? Sites will no longer have the power of changing the colors of visited links at all, but the user will still be able to differentiate. In a sense, the user’s view and the code’s view of the page would be a little different.
I am not sure how much CSS/JS engine hacking this requires though.
[1] https://wiki.mozilla.org/Security/CSP/HistoryModule
11. Arvind | February 21, 2010 at 4:38 am
Arvind | February 21, 2010 at 4:38 am
Ah, looks like safe-history and SafeHistory are different things :-) D’oh! This confusion came up earlier in discussions at Mozilla yesterday; I didn’t realize the reason.
Yes, Mozilla apparently have plans to implement just what you said, under the assumption that 1. it doesn’t require too much hacking of the engine 2. it doesn’t introduce a performance hit. Let’s wait and see.
12. anonymous | February 21, 2010 at 5:00 am
anonymous | February 21, 2010 at 5:00 am
(I can’t see a reply button under your comment)
I would suggest talking to the Chrome people – their code is cleaner (newer) and they might be able to achieve this sooner (and hopefully this might push the other browser vendors too).
13. Arvind | February 21, 2010 at 5:03 am
Arvind | February 21, 2010 at 5:03 am
I limited the max threading depth because the column width is too narrow.
There are other researchers apparently working with the Chrome people on related issues. I do plan to get in touch with them soon-ish.
14. HS | February 19, 2010 at 6:50 am
HS | February 19, 2010 at 6:50 am
Out of curiosity, what are the other techniques for history sniffing besides reading the ‘visited’ style of links?
15. Arvind | February 19, 2010 at 6:52 am
Arvind | February 19, 2010 at 6:52 am
Cache timing.
16. Ubercookies Part 2: History Stealing meets the Social Web « 33 Bits of Entropy | February 19, 2010 at 8:02 am
[…] 19, 2010 Recap. In the previous article I introduced ubercookies — techniques that websites can use to de-anonymize visitors. I discussed […]
17. How Google Docs Leaks Your Identity « 33 Bits of Entropy | February 22, 2010 at 8:11 pm
[…] In the previous two articles in this Ubercookies series, I showed how an arbitrary website that you visit can learn […]
18. History Stealing: It’s All Shades of Grey « 33 Bits of Entropy | March 9, 2010 at 7:33 am
[…] 9, 2010 Previous articles in this series showed that ‘Ubercookies’ can enable websites to learn the identity of any visitor by […]
19. Cookies, Supercookies and Ubercookies: Stealing the Identity of Web Visitors — MPThree Consulting Inc. | March 14, 2010 at 4:02 pm
[…] Cookies, Supercookies and Ubercookies: Stealing the Identity of Web Visitors A web analytics dream: keeping visitors from being anonymous. If you’re not a web analyst, don’t read this–you’ll cry at how much your life is an open book. […]
20. Benlog » Protecting against web history sniffing attacks: an alternative | March 31, 2010 at 4:18 pm
[…] by putting up a few links and checking to see how your browser is rendering them. Arvind explained the shockingly bad outcome of this small flaw a few weeks […]
21. Jim B | April 5, 2010 at 4:03 pm
Jim B | April 5, 2010 at 4:03 pm
Firefox trunk just plugged this 10 year old hole:
http://blog.mozilla.com/security/2010/03/31/plugging-the-css-history-leak/
22. Tess Elliott | April 29, 2010 at 4:52 am
Tess Elliott | April 29, 2010 at 4:52 am
This is depressing: I went directly to Firefox to download “Safe History” and it is not compatible with the newest version! Any other ideas? Do I need to wipe my history continually?
23. Yet Another Identity Stealing Bug. Will Creeping Normalcy be the Result? « 33 Bits of Entropy | June 1, 2010 at 9:39 am
[…] should be familiar to readers of this blog. I’ve recently written about doing this via history stealing, then a bug in Google spreadsheets, and now we have this. While the spreadsheets bug was fixed, the […]
24. Anže | April 8, 2011 at 3:02 pm
Anže | April 8, 2011 at 3:02 pm
I tried to make my browser protect my pricacy (by deleting cookies, supercookies, ubercookies,…) but found it *very* difficult to do properly because you have no feedback So I setup a site that tries every method of tracking I could think of and tells you the results:
http://www.canyoutrackme.com/
BTW, nice blog – if you check the “links” section you will find yourself very high on the list. ;)
25. Jeremy Moskowitz | August 19, 2011 at 11:50 am
Jeremy Moskowitz | August 19, 2011 at 11:50 am
Here’s my input. A short video for how to stop Supercookies on Windows systems. Geared for IT geeks http://t.co/bRsiKpJ
26. Andres | January 25, 2013 at 3:13 pm
Andres | January 25, 2013 at 3:13 pm
There is an easy way to stop this. Just install deep freeze in your computer and you won’t have much browsing history.
27. Arvind Narayanan | January 25, 2013 at 6:14 pm
Arvind Narayanan | January 25, 2013 at 6:14 pm
That’s certainly a good idea for Internet kiosks and such, but for regular users that would be throwing the baby out with the bathwater.
28. Andres | January 26, 2013 at 6:41 am
Andres | January 26, 2013 at 6:41 am
Really not. I’m using deep freeze for 2 years now and I don’t get troyans (well sometimes they infect me, but once rebooted, they are gone), my desktop doesn’t change, so I can apply automation tools to save me time, the performance of my PC is always optimal and I’m really happy with it.